数据类型进阶操作¶
1. 数值类型进阶操作¶
python中,关于数值,数学领域相关常用的模块有:
- 内置模块:math(数学),random(随机),decimal(十进制数值),statistics(统计分析),fractions(有理数)
- 第三方模块:numpy(科学计算),pandas(数据分析),SymPy(符号计算)
| 函数(必填参数[, 选填参数, ]) | 描述 |
|---|---|
| int(x) | 将x转换为一个整数。 |
| float(x) | 将x转换到一个浮点数。 |
| pow(x, y) | 计算x的y次幂的结果,等价于x**y。 |
| abs(x) | 求数字x的绝对值。 |
| divmod(a, b) | 计算a除以b的结果,结果为(商,余数)。 |
| round(x [,n]) | 返回浮点数 x 的舍入整数值(遵循四舍六入五偶数规则),如指定n值则代表保留小数点后的n位小数。 |
| max(a, b,c,...) | 求指定参数的最大值。 |
| min(a, b,c,...) | 求指定参数的最小值。 |
| 模块.方法(必填参数) | 描述 |
|---|---|
| math.ceil(x) | 对数字x进行向上取整。 |
| math.floor(x) | 对数字x进行地板取整。 |
| math.modf(x) | 返回x的整数部分与小数部分,整数部分以浮点型表示。 |
| math.sqrt(x) | 返回数字x的平方根。 |
| random.random() | 随机生成一个[0,1)区间范围的实数。 |
| random.randint(a,b) | 随机生成一个[a,b]区间范围的整数。 |
| random.choice(seq) | 从序列中随机挑选一个成员。 |
| random.shuffle(list) | 将序列的所有元素重新随机排序,也叫洗牌。 |
| decimal.Decimal(x) | 把x转换成decimal数值。x可以是字符串,整型,浮点型,默认为"0"。 |
| fractions.Fraction(x) | 把x转换成一个分数,类型为字符串,但是支持数值计算。 |
| statistics.mean(Iterable) | 对一个可迭代数据进行计算,求平均值。 |
| statistics.median(Iterable) | 对一个可迭代数据进行计算,求中位数(中间值)。 |
| statistics.mode(Iterable) | 对一个可迭代数据进行计算,求首次出现的众数(出现最多的值)。 |
| statistics.multimode(Iterable) | 对一个可迭代数据进行计算,求所有众数。 |
"""int(x) 将x转换为一个十进制整数。"""
# 字符串转整数,字符串只能由数字组成的
data: int = int("35")
print(data, type(data))
# 可以把其他的进制数值字符串转换成十进制整数
data: int = int("0b1010", base=2)
print(data, type(data))
data: int = int("0o1010", base=8)
print(data, type(data))
# 取整
print(int(3.999999999)) # 3
# 特殊情况:浮点数精度在Python中默认是16,达到16就会舍入
print(int(3.99999_99999_99999_9)) # 4
"""float(x) 将x转换到一个浮点数。"""
data: float = float("3.5")
print(data, type(data))
"""abs(x) 求绝对值 |x|"""
print(abs(100)) # 100
print(abs(-10)) # 10
"""pow 幂运算"""
print(pow(2,3)) # 8 等价于2**3次方
"""divmod 求商和余数"""
print(divmod(10, 3)) # (3, 1)
print(divmod(-10, 3)) # (-4, 2)
"""round 四舍五入取整,实际上是四舍六入五偶数"""
print(round(3.4)) # 3
print(round(3.6)) # 4
print(round(3.5)) # 4
print(round(2.5)) # 2
"""取最大值"""
print(max(10, 12, 15, 20)) # 20
# 实际上,只要是支持比较运算符的数据类型,都可以使用max或者min求最大值与最小值
print(max("a", "B", "+", "1")) # a
print(max([1,2], [1,3], [2,1], [3])) # [3]
"""取最小值"""
print(min(10, 12, 15, 20)) # 10
# 同max,只要是支持比较的数据类型,都可以使用max或者min求最大值与最小值
print(min("a", "B", "+", "1")) # +
print(min([1,2], [1,3], [2,1], [3])) # [1, 2]
"""math.ceil 向上取整"""
# 表示引入数学模块(python文件)
import math
print(math.ceil(3.1)) # 4
print(math.ceil(3.0)) # 3
# 注意:
print(math.ceil(3.00000_00000_00000_1)) # 3
print(math.ceil(4.00000_00000_00000_1)) # 4
"""math.floor 向下取整(地板取整)"""
import math
print(math.floor(3.1)) # 3
print(math.floor(3.9)) # 3
# 注意:
print(math.floor(3.99999_99999_99999_9)) # 4
print(math.floor(2.99999_99999_99999_9)) # 3
"""提取一个数字的整数部分和小数部分,结果格式:(浮点数部分,整数部分)"""
import math
print(math.modf(3.1415)) # (0.14150000000000018, 3.0)
print(math.modf(-3.1415)) # (-0.14150000000000018, -3.0)
"""sqrt 平方根"""
import math
print(math.sqrt(4)) #2.0
print(math.sqrt(9)) # 3.0
"""随机数"""
import random
# random.random() 生成一个0~1之间的随机实数 [0,1) 不包含1
print(random.random())
# random.randint() 生成一个指定范围[a,b]的随机整数
print(random.randint(1,100))
# random.choice 随机抽取一个成员
print(random.choice(["小明", "小红", "小白"]))
print(random.choice("ABCDEF"))
# random.shuffle(列表) 随机打乱序列的成员排列顺序,这个shuffle在很多编程语言里面都有,是基于洗牌算法实现的。
data: list = ["A", "B", "C"]
random.shuffle(data) # 注意:此处不需要写等号了,因为shuffle是直接在内存地址上修改该数据。
print(data)
"""
decimal 十进制浮点数操作模块
python默认的浮点数类型会默认在内存中以二进制形式来进行计算,而十进制的小数转换成二进制时很容易形成无限循环或无限不循环小数。
当出现无限小数时,计算机存储二进制的位数是有上限的,超过则截断,这样就会导致浮点数的计算无法得到精确结果,只能得到一个近似值。
decimal比内置的浮点数在精度上更高,因此可以获得更加接近于结果的近似值,
同时,使用decimal在十进制浮点数计算时,也可以减少出现精度丢失的问题
"""
from decimal import Decimal, getcontext
# 设置精度为4位小数
getcontext().prec = 4
print(Decimal(0.1), type(Decimal(0.1))) # 0.1000000000000000055511151231257827021181583404541015625 <class 'decimal.Decimal'>
print(0.1+0.2) # 0.30000000000000004
print(Decimal(0.1) + Decimal(0.2)) # 0.3000000000000000444089209850062616169452667236328125
print(Decimal('0.1') + Decimal('0.2')) # 0.3
"""fractions,有理数模块,也叫分数处理模块"""
from fractions import Fraction
print(Fraction(0.5)) # 1/2
print(Fraction(1, 2)) # 1/2
print(Fraction("1/2")) # 1/2
print(Fraction("1/4") + Fraction("2/3")) # 11/12
"""statistics 统计模块"""
import statistics
# 均值(Mean)
print(statistics.mean([1, 2, 3, 4, 5])) # 4
print(statistics.mean([1, 2, 3, 4, 5, 12])) # 4.5
# 中位数(Median)
print(statistics.median([1, 2, 3, 4, 15])) # 3
print(statistics.median([1, 2, 3, 4, 5, 6])) # 3.5
# 众数(Mode)
print(statistics.mode( [1, 2, 4, 4, 4, 2, 2])) # 2
print(statistics.mode( ["A", "B", "B", "B", "D", "D", "D"])) # B
print(statistics.multimode( [1, 2, 2, 2, 4, 4, 4])) # [2, 4]
print(statistics.multimode( ["小明", "小红", "小红", "小红", "小明", "小白", "小明"])) # ['小明', '小红']
2. 字符串进阶操作¶
2.1 常用函数与方法¶
python中,除了字符串本身操作,常见的字符、文本相关操作的模块:
内置模块:string(字符串模块),re(正则表达式),json(JSON数据)
第三方模块:xpath(网页文档结构查询),BeautifulSoup(bs4,解析网页)
| 函数(必填参数) | 描述 |
|---|---|
| str(x) | 将x转换为字符串 |
| len(x) | 获取字符串x的长度 |
| max(x) | 返回字符串x中最大值的字符 |
| min(x) | 返回字符串x中最小值的字符 |
| ord() | 获取指定字符在unicode编码中的码点。 |
| chr() | 获取unicode编码中指定码点对应的字符。 |
| 方法名(必填参数,选填参数=默认值[, 选填参数, ...]) | 描述 |
|---|---|
| s.format(args, *kwargs) | 格式化字符串s。如果没有特殊要求建议改用f-string。 |
| s.count(sub[, start[, end]]) | 计算字符串s中子串sub出现的次数。 如果指定start或end则返回指定范围内的出现次数。 |
| s.isdigit() | 字符串s是否只包含数字,是则结果为True,否则False。 |
| s.isalpha() | 字符串s是否只包含字母,是则结果为True,否则False。 |
| s.isalnum() | 字符串s是否只包含字母或数字,是则结果为True,否则False。 |
| s.startswith(prefix[, start[, end]]) | 字符串s是否以子串prefix开头,是则结果为True,否则False。 如果指定start或end,则判断指定范围内是否以子串prefix开头。 |
| s.endswith(suffix[, start[, end]]) | 字符串s是否以子串suffix结束,是则结果为True,否则False。 如果指定start或end,则判断指定范围内是否以子串suffix结束。 |
| s.find(sub[, start[, end]]) | 获取子串sub在字符串s中首次出现的下标,如果没有出现,则结尾为-1。 如果指定start或end,则获取指定范围内子串sub首次出现的下标。 |
| s.index(sub[, start[, end]]) | 同find()方法,只是当子串sub不在字符串s中则抛出异常。 |
| s.capitalize() | 字符串s的第一个字符如果是字母则改为大写,其他字符保持不变。 |
| s.title() | 把字符串s标题化 ,即所有单词改为首字母大写。 |
| s.lower() | 转换字符串s中的所有大写字母为小写字母。 |
| s.upper() | 转换字符串s中的所有小写字母为大写字母。 |
| s.strip([chars]) | 删除字符串s两边连续的chars字符,如果不指定chars的值,则默认删除空格。 |
| s.rstrip([chars]) | 删除字符串s右边末尾的chars字符,如果不指定chars的值,则默认删除空格。 |
| s.lstrip([chars]) | 删除字符串s左边开头的chars字符,如果不指定chars的值,则默认删除空格。 |
| s.join(iterable) | 以字符串s作为拼接符,把可迭代类型iterable中所有的元素合并成一个新字符串。 |
| s.split(sep=None, maxsplit=-1) | 以子串sep作为分隔符,把字符串sep进行分割成列表。 如果指定maxsplit,则只把字符串s分隔成 由 maxsplit+1 个子字符串组成的列表。 |
| s.splitlines([keepends]) | 以换行符('\r', '\r\n', '\n')作为分隔符,把字符串s分割成列表。 如果指定keepends的值为False,则结果列表中剔除换行符, 如果为True,则保留换行符。 |
| s.replace(old, new, count=-1) | 把字符串s中的new替换成old,如果指定count的值,则替换次数最多为count次。 |
| s.translate(table) | 根据指定映射表table来替换字符串s中的多个字符。 映射表table通常可以使用str.maketrans() 来创建。 |
| s.encode(encoding='UTF-8', errors='strict') | 以 encoding 指定的编码格式对字符串s进行编码。 如果编码出错则抛出异常,除非指定errors的值为'ignore'或'replace'。 |
| b.decode(encoding='UTF-8', errors='strict') | 以 encoding 指定的编码格式对字节串b进行解码。 如果解码出错则抛出异常,除非指定errors的值为'ignore'或'replace'。 |
"""字符串.format() 格式化字符串"""
print("商品《{}》的价格为{:.2f}元。".format("西游记", 1000)) # 本次购买商品总共消费1000元。
print("商品《{1}》的价格为{0:.2f}元。".format(1000, "西游记")) # 本次购买商品总共消费1000元。
print("商品《{title}》的价格为{money:.2f}元。".format(title="西游记", money=1000)) # 本次购买商品总共消费1000元。
"""字符串.count(子串) 统计子串在字符串中出现的次数"""
print("hello world".count("l")) # 3
"""字符串.isdigit() 如果字符串s只包含数字则返回 True 否则返回 False"""
print("3.1415".isdigit()) # False
print("10000".isdigit()) # True
"""
字符串.startswith(子串) 判断字符串是否以子串开头
字符串.endswith(子串) 判断字符串是否以子串结尾
字符串.find(子串) 获取子串首次在字符串的下标位置,找不到结果为-1,找到则返回首次出现的下标位置,从0开始[不报错!],如果希望从右往左查,则使用rfind
字符串.index(子串) 获取子串首次在字符串的下标位置,找不到则报错,找到则返回首次出现的下标位置,从0开始[报错!]
"""
# 判断某个人是否姓王
username: str = "王晓明"
print(username.startswith("王")) # True
# 判断某个人是否姓王或黄
print(username.startswith(("王", "黄"))) # True
# 判断字符串是否是QQ邮箱
mail: str = "649641514@qq.com"
print(mail.endswith("@qq.com")) # True
# 判断文件是否是图片格式
file_name: str = "1.png"
print(file_name.endswith(("gif", "png", "jpg", "jpeg"))) # True
# 判断某个人的名字里面是否有"明"
name: str = "江小白"
print(name.find("江")) # 0
print(name.find("白")) # 2
print(name.find("大")) # -1
print(name.index("江")) # 0
print(name.index("白")) # 2
# print(name.index("大")) # 报错
"""
字符串.capitalize() 字符串首个字母大写,如果字符串首个字符不是字母,则不会转换大写
字符串.title() 按广告标题格式,把字符串那种所有单词的首字母转换成大写
字符串.lower() 把字符串中的英文字母转换成小写
字符串.upper() 把字符串中的英文字母装换成大写
"""
print("hello moluo".capitalize()) # Hello moluo
print("1hello moluo".capitalize()) # 1hello moluo
print("hello world".title()) # Hello World
print("get".upper()) # GET
print("POST".lower()) # post
"""
字符串.strip() 去除字符串的两边空格,注意:字符串中间的空格不会被删除,只会删除两边连续的空格
字符串lstrip() 去除字符串的左边空格,注意:字符串中间的空格不会被删除,只会删除左边连续的空格
字符串.rstrip() 去除字符串的右边空格,注意:字符串中间的空格不会被删除,只会删除右边连续的空格
"""
msg: str = " hello wolrd "
ret: str = msg.strip()
print(len(ret), f"{ret!r}")
ret: str = msg.lstrip()
print(len(ret), f"{ret!r}")
ret: str = msg.rstrip()
print(len(ret), f"{ret!r}")
"""
子串.join(序列) 【合并】使用指定子串作为拼接符,把序列中所有成员拼接成一个字符串
字符串.split(子串) 【分割】使用子串作为分隔符,把字符串按子串分割成多段,组成一个列表[列表至少有一个成员]
字符串.splitlines() 【分割】 按行分割
"""
data: list = ["北京市", "海淀区", "中关村"]
print("-".join(data)) # 北京市-海淀区-中关村
addr: str = "北京市-海淀区-中关村"
print(addr.split("-")) # ['北京市', '海淀区', '中关村']
print(addr.split("-",1)) # ['北京市', '海淀区-中关村']
# # 如果无法分割,也不会报错,但是会把整个字符串作为一个整体,保存到列表中作为一个成员
addr: str = "北京市:海淀区:中关村"
print(addr.split("-")) # ['北京市:海淀区:中关村']
content: str = """云想衣裳花想容,
春风拂槛露华浓。
若非群玉山头见,
会向瑶台月下逢。
"""
for item in content.splitlines():
print(">>> ", item)
"""
字符串.replace(old, new, num) 字符串替换
字符串.translate(table) 字符串按映射表批量替换
"""
# 默认是全部替换
content: str = "Welcome to Chengdu, Chengdu is a city of rich history and vibrant culture."
# 把 Chengdu 换成 Beijing
ret: str = content.replace("Chengdu", "Beijing")
print(ret) # Welcome to Beijing, Beijing is a city of rich history and vibrant culture.
# 也可以指定替换次数
ret: str = content.replace("Chengdu", "Beijing", 1)
print(ret) # Welcome to Beijing, Chengdu is a city of rich history and vibrant culture.
# 批量替换
trans_table: dict = str.maketrans("abcdefghijklmnopqrstuvwxyz", "uefmacjvrbiqykpwnsztghodlx")
text: str = "hello world"
new_text: str = text.translate(trans_table)
print(new_text) # 输出:vaqqp opsqm
练习:判断字符串mail是否是合法的邮箱格式。
mail: str = "1234@qq.com"
at: int = mail.index("@")
print(at) # 4
dot: int = mail.index(".")
print(dot) # 7
if at < dot:
print("邮箱合法!") # 以后用正则判断更为简便准确!当然要最准确的话,就要通过发送邮件来证明。
2.2 字符编码¶
我们前面学习了关于二进制数字的表示和运算,知道计算机内部实际上只能识别和存储二进制数据。实际上,不仅是我们所使用的浮点型、整型、布尔型都是计算机内部通过转换二进制数值得到的,连字符串也是不能直接存储在计算机或网络中的,因为字符串是一种由字符组成的不可变序列类型,同样字符也并非二进制格式的数字。
那么,如何让只能识别二进制的计算机也能存储字符呢?很简单,我们只需要把字符和二进制数字绑定起来,让计算机存储字符对应的二进制数字就可以了。
因此,产生了三个概念:
- 为了与数学上的二进制数字进行区分,所以这些代替字符存储到计算机中的二进制数字,被称之为“码点(code point)”,码点存储在计算机中是二进制,为了方便阅读,计算机一般显示为十六进制。
- 把字符转换计算机可以存储的码点,这个操作过程被称之为“编码(encode)”。
- 把计算机存储的码点转换成人类可读的字符, 这个操作过程被称之为“解码(decode)”。
接下来,我们学习下计算机是如何进行编码和解码的?
2.2.1 ASCII编码¶
我们都知道,计算机最早起源于美国,所以美国人最先参考电报码实现了让计算机把字符和二进制数字(码点)绑定起来。美国人使用的字符实际上就是英文、数字,以及一些符号。因此他们把这些可能用上的128个字符与二进制的0~127进行一一对应的绑定,形成了一张映射表格,由此实现了字符在计算机中可以使用一个字节长度的二进制数字(码点)来表示的方案(实际只使用了7bit,最高位默认为0)。这个方案就叫ASCII(American Standard Code for Information Interchange,美国信息互换标准代码)编码表,也叫ASCII编码标准或ASCII字符集,由33个无法打印的控制字符与95个可打印的字符、数字、符号组成。如下:
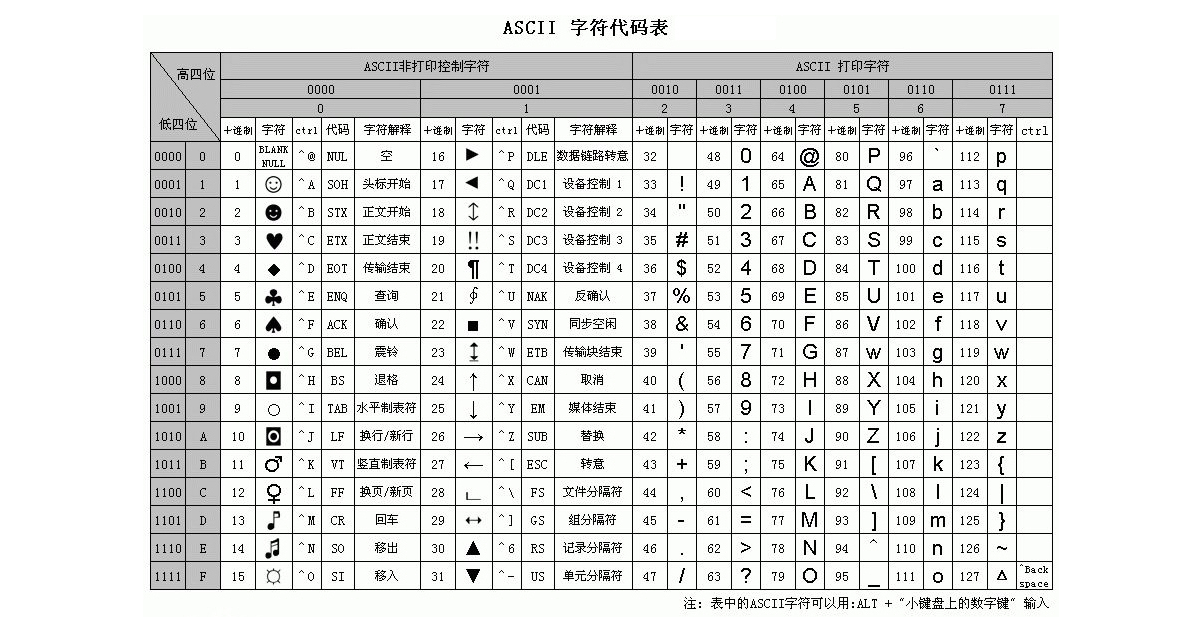
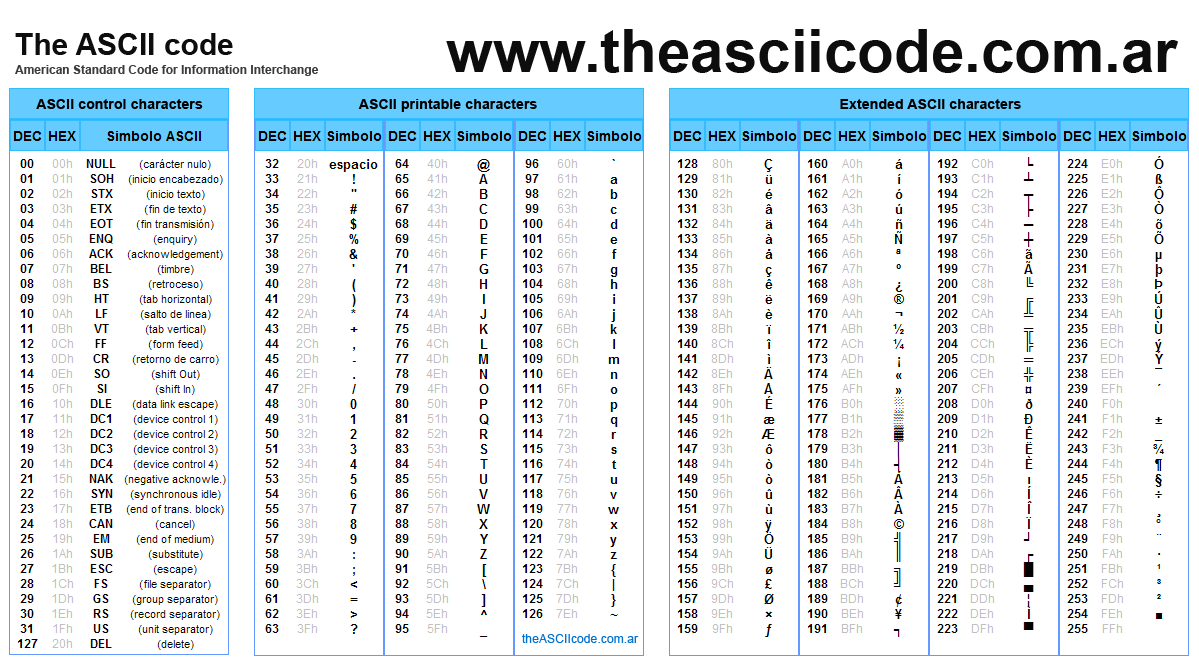
在随后几年里,计算机普及到了欧洲,字符显示问题再次出现,原本的ASCII编码只是解决美国人的字符表示问题,无法将欧洲人的使用字符表示出来,因此为了让计算机能表示更多的欧洲常用字符,ASCII进行了扩展,把1个字节最高位也用上了,码点范围:128~255。于是出现了EASCII(ASCII扩展编码表,如下图右)。
2.2.2 GBK编码¶
欧洲的字符显示问题是解决了,但是亚洲这边像中文,韩文,日文等字符以及相关符号也需要在计算机上显示。可是一个字节8位二进制数字(码点)已经被西方国家占满了。即便没有占满,因为中文常用字多大几千上万个,即便单个字节长度的码点全部用来表示中文最多也只能有256个。所以我国科学家就干脆自己重新设计一张新的编码表,并使用多个字节长度的二进制数字来表示字符,并把二进制数字(码点)127之后对应的欧洲奇怪字符全部清掉,重新编排规定:小于127的二进制数字(码点)对应的依然是ASCII编码中的字符,但两个大于127的二进制数字(码点)连在一起写时,就表示一个汉字,前面的一个字节(称之为高字节)的码点范围:0xA1(0b10100001)0xF7(0b11110111),后面一个字节(称之为低字节)的码点范围则是:0xA1(0b10100001) 0xFE(0b11111110),于是这个新的编码表就可以组合出大约8000多个二进制数字(码点),包含6763个简体汉字,这张新的编码表被叫做GB2312编码表。
同时在GB2312编码表里,还把数学符号、罗马字母、希腊字母、注音字母等等都编进去了,连在 ASCII 里本来就有的数字、标点、字母都统统重新编了两个字节长度的码点,这就是常说的“全角”字符,而原来在127码点以下的那些字符就叫”半角”字符了。
但是随着计算机在国内各行各业不断的普及,8000个字符还是抓襟见肘,于是我国再次编排了一份新的编码表,规定:首字节的码点范围: 0x81~0xFE,尾字节的码点在 0x40-0xFE,但剔除0x7F码点,一下子扩充了23940个码点。于是,新的编码表包含GB2312编码表在内,共收录21886个字符,共有21003个汉字字符(包括简、繁体字)。而这张新的编码表就叫GBK编码表,也叫GBK编码标准或GBK字符集。
之后的发展中,因为又收录了少数民族的字符,于是GBK编码再次扩展出了GB18030编码表。
2.2.3 Unicode编码¶
与此同时,其它国家也都开发出一套编码方式,即本国文字符号和二进制数字的对应表。而不同国家彼此间的编码方式是互不支持的,这会导致很多问题。例如:中文网站可以在韩国、日本的电脑上显示,但是日本、韩国的网站在中国的电脑上部分字符无法显示或显示错乱。于是ISO国际化标准组织为了解决不同国家不同字符编码冲突的问题,搞了一张收录了世界上所有国家的字符的万国编码表,这就是Unicode编码(又称统一码、万国码、单一码,Unicode字符集、Unicode编码标准)。
Unicode编码使用两个字节即六万多个二进制数字来对应各个国家所有的字符(包括甲骨文)。就这样,每个国家都使用统一的Unicode编码就不存在不同国家计算机的编码问题了。
我们可以通过python内置的函数chr与ord对获取字符对应的unicode码点,或者通过unicode码点获取对应的字符。
2.2.4 utf-8编码¶
Unicode的编码特点是对于任意一个字符都需要两个字节来存储,但美国人不乐意了,之前明明可以通过ASCII编码使用一个字节就可以存储的字符,现在为了兼容其他语言而需要两个字节了,足足浪费了一倍的存储空间。于是美国人出手了,他们又重新搞了一份新的统一编码表:utf-8(8-bit Unicode Transformation Format)编码表,也叫utf-8字符集。这是一种针对Unicode编码的可变长字符转换方式,根据具体不同的字符计算出需要的字节,对于ASCII编码范围的字符就用一个字节,而且符号与二进制数字的对应也是一致的,因此utf-8是兼容ASCII码表的。因为utf-8在不同字符长度之间是可变的,因此使用utf-8编码表示数据比Unicode编码占用的空间要少,因此目前大多数的编程语言,包括Python3都是默认使用的utf-8编码。
注意,因为中文数量众多,所以utf-8编码中对于中文默认是用三个字节存储的,我们可以在Python中通过字符串的encode方法把文字转换成utf-8格式的编码字符。
2.3 Bytes类型¶
我们可以通过type查看上面的变量a和b,代码:
bytes(字节串,也叫二进制安全格式字符串)是Python中用于处理二进制数据的基本类型,是由一串字节(byte)组成的不可变序列类型数据。每个字节由8位二进制数表示,取值范围是0到255。字节串可以表示任意的二进制数据,包括各种计算机存储的非字符组成的文件(如图片、音频、视频等)的内容和网络传输中的数据包,当然也可以用于表示字符的编码形式。
2.3.1 基本使用¶
Python解释器主要提供了三种方式给我们创建字节串:
1.如果字符内容都是ASCII码对应的字符,则可以通过直接字面量来创建bytes类型,即在字符串之前添加 b 来创建。
print(b'', type(b'')) # b'' <class 'bytes'>
print(b'A', type(b'A')) # b'A' <class 'bytes'>
print(b'Moluo', type(b'Moluo')) # b'Moluo' <class 'bytes'>
# print(b'中', type(b'中')) # 报错:SyntaxError: bytes can only contain ASCII literal characters
2.使用bytes()类型函数将字符串按指定字符集转换成字节串,如果不指定字符集则默认使用 UTF-8字符集。
b1: bytes = bytes()
print() # b''
b2: bytes = bytes(range(48, 48+10))
print(b2) # b'0123456789'
b3: bytes = bytes(range(65, 65+26))
print(b3) # b'ABCDEFGHIJKLMNOPQRSTUVWXYZ'
b4: bytes = bytes(5)
print(b4)# b'\x00\x00\x00\x00\x00'
b5: bytes = bytes('welcome to 北京', encoding='UTF-8')
print(b5) # b'welcome to \xe5\x8c\x97\xe4\xba\xac'
3.【最常用】就是上面我们使用过的,调用字符串本身的encode() 方法将字符串按指定字符集转换成字节串。如果不指定字符集,默认使用 UTF-8 字符集。
s: str = 'welcome to 北京。'
b: bytes = s.encode(encoding='utf-8')
print(b) # b'welcome to \xe5\x8c\x97\xe4\xba\xac\xe3\x80\x82'
s: str = 'welcome to 北京。'
b: bytes = s.encode(encoding='gbk')
print(b) #b'welcome to \xb1\xb1\xbe\xa9\xa1\xa3'
2.3.2 格式转换¶
字符串编码为字节串
s: str = 'welcome to 北京。'
b: bytes = s.encode(encoding='gbk')
print(b) #b'welcome to \xb1\xb1\xbe\xa9\xa1\xa3'
字节串解码为字符串:
3. 列表进阶操作¶
3.1 切片进阶操作¶
在python中,可变序列类型的切片操作不仅可以用于获取部分成员,还可以用于添加、删除、修改单个成员或多个成员。
"""获取指定区间范围的部分成员"""
data: list = [0, 1, 2, 3, 4, 5]
ret: list = data[1:4]
print(ret) # # 获取索引1到3的成员,结果为[1, 2, 3]
"""添加1个或多个成员"""
data: list = [0, 1, 3, 4]
data[2:2] = [2]
print(data) # # 在索引2的位置插入2,结果为[0, 1, 2, 3, 4]
"""删除1个或多个成员"""
data: list = [0, 1, 2, 3, 4]
data[1:3] = [] # 删除索引1到2的成员,结果为[0, 3, 4]
print(data) # [0, 3, 4]
"""修改1个或多个成员"""
data: list = [0, 1, 2, 3, 4]
data[1:3] = [8, 9]
print(data) # 将索引1到2的成员修改为8和9,结果为[0, 8, 9, 3, 4]
3.2 多级容器操作¶
goods_list: list = [
{"title": "诛仙", "price": 31.50, "size": "65万字"},
{"title": "魔道祖师", "price": 50.00, "size": "130万字"},
{"title": "长生界", "price": 86.80, "size": "200万字"},
]
3.3 常用函数与方法¶
| 函数(必填参数) | 描述 |
|---|---|
| list(x) | 将x转换为列表 |
| len(x) | 获取列表长度 |
| max(x) | 返回列表x中最大值的元素 |
| min(x) | 返回列表x中最小值的元素 |
| 方法(必填参数, 可选参数=默认值 [, 可选参数]) | 描述 |
|---|---|
| list.count(x) | 统计成员x在列表中出现的次数,与字符串操作一样。 |
| list.index(x [, i, j]) | 从列表中找出成员x首次出现的索引位置,与字符串操作一样。 如果指定开始下标i或结束下标j则返回指定范围内的首次出现下标。 |
| list.insert(i, x) | 将x插入列表中指定下标i位置上,等价于:s[i:i] = [x]如果要批量添加成员,可以使用切片操作 |
| list.append(x) | 在列表末尾添加1个新成员x,等价于:s[len(s):len(s)] = [x]。如果要批量添加成员,可以使用切片操作 |
| list.extend(t) | 在列表末尾一次性追加另一个序列t中的多个值(用新列表扩展原来的列表), 等价于: s[len(s):len(s)] = t) 或 s += t |
| list.pop([i=-1]) | 提取列表中在下标i上的成员,并将其移除。 |
| list.remove(x) | 移除列表中首次出现的成员x。 |
| list.reverse() | 对列表自身所有元素进行逆序重排。 |
| list.sort(key=None, reverse=False) | 对列表自身按key选项指定的排序方法对所有成员进行排序。 reverse选项用于设置是否反向排序,True表示反向排序。 |
| list.clear() | 清空列表,等价于del s[:] |
| list.copy() | 复制列表,等价于s[:] |
"""把其他类型容器转换成列表"""
data: list = list("abdcef")
print( data ) # ['a', 'b', 'd', 'c', 'e', 'f']
# 特殊:对字典进行转换,只会保留键作为列表的成员
data: list = list({"name":"xiaoming", "age": 16})
print( data ) # ['name', 'age']
"""计算列表成员数量"""
data: list = [1,2,3]
print(len(data)) # 3
"""计算最大值,最小值"""
data: list = [11,2,13]
ret: int = max(data)
print(ret) # 13
ret: int = min(data)
print(ret) # 2
# 特殊情况:因为max和min内部使用了大小于号来比较的,所以如果一个列表中出现了不同数据类型,则无法计算最大最小值,反而报错
data: list = [11, "2", 13]
ret: int = max(data)
print(ret) # 报错:TypeError: '>' not supported between instances of 'str' and 'int'
""" 列表.count(成员) 统计列表中指定成员的数量 """
data: list = ["A", "B", "C", "A", "D", "A"]
ret: int = data.count("A")
print(ret) # 3
"""列表.index() 查找成员首次出现的下标,不存在,会报错"""
data: list = ["A", "B", "C", "A"]
# ret: int = data.index("W")
# print(ret) # 不存在,会报错,ValueError: 'W' is not in list
ret: int = data.index("A")
print(ret) # 0
"""
列表.insert(index, 成员) 在列表中下标位置初插入成员,插入以后,原下标对应的成员自动往后排序
列表.append(成员) 列表末尾追加成员
列表.extend(序列) 合并列表,把第二个列表的成员合并到第一个列表
"""
data: list = ["小明", "小红", "小白"]
data.insert(0, "小黑")
print(data) # ['小黑', '小明', '小红', '小白']
data: list = ["小明", "小黑", "小红"]
data.append("小白")
print(data) # ['小明', '小黑', '小红', '小白']
data: list = ["A", "B", "C"]
print(id(data), data) # 1952182872832 ['A', 'B', 'C']
data.extend(["X", "Y", "Z"])
print(data) # ['A', 'B', 'C', 'X', 'Y', 'Z']
print(id(data), data) # 1952182872832 ['A', 'B', 'C', 'X', 'Y', 'Z'] 从这里可以看到,data还是原来的data,并没有产生新的数据,还是使用原来的内存。
"""
列表.pop([index=-1]) 移除指定下标的成员
列表.remove(x) 删除左起第一个遇到的成员x
"""
data: list = ["A", "B"]
item: str = data.pop()
print(item) # B
item: str = data.pop()
print(item) # A
# item: str = data.pop()
# print(item) # 针对空列表,不能使用pop会报错:IndexError: pop from empty list
# 也可以基于pop删除指定下标的成员
data: list = ["A", "B", "C", "D"]
ret: str = data.pop(1)
print(ret) # B
print(data) # ['A', 'C', 'D']
# 删除左起第一个遇到的成员x
data: list = [1, 2, 3, 2, 1]
data.remove(2)
print(data)
"""
列表.reverse() 对列表自身进行逆序重排
random.shuffle(data) 随机打乱列表,对列表进行洗牌
列表.sort() 对列表成员进行正序排序,按数字或字典序从小到大排列
列表.sort(reverse=True) 对列表成员进行逆序排序,按数字或字典序从大到小排列
"""
# 反序
data: list = [2, 1, 5, 3, 6, 4, 7, 8, 9, 10]
data.reverse()
print(data) # [10, 9, 8, 7, 4, 6, 3, 5, 1, 2]
# 洗牌
import random
data: list = [1, 3, 5, 7, 9]
random.shuffle(data)
print(data) # [7, 1, 5, 9, 3]
# 正序排序
data: list = [9, 5, 1, 3, 7]
data.sort()
print(data) # [1, 3, 5, 7, 9]
data: list = ["A", "D", "B", "E", "C"]
data.sort()
print(data) # ['A', 'B', 'C', 'D', 'E']
# 逆序排序
data: list = [20, 13, 9, 5, 1, 11, 78, 1]
data.sort(reverse=True)
print(data) # [78, 20, 13, 11, 9, 5, 1, 1]
# # 特殊情况:sort排序也是基于大小于号进行先后排序的,所以列表中存在不同类型数据时。会报错。
# data: list = ["A", "D", 9, 5, 1, "B", "E", "C"]
# data.sort()
# print(data) # TypeError: '<' not supported between instances of 'int' and 'str'
# 后面,我们会学习到lambda匿名函数就可以解决上面的报错问题,代码如下:
data: list = ["A", "D", 9, 5, 1, "B", "E", "C"]
data.sort(key=lambda a: str(a))
print(data) # [1, 5, 9, 'A', 'B', 'C', 'D', 'E']
# 甚至可以对字典中的成员进行排序
data: list[dict] = [
{"id": 6, "name": "商品1", "price": 49.90},
{"id": 2, "name": "商品2", "price": 39.90},
{"id": 4, "name": "商品4", "price": 89.90},
{"id": 3, "name": "商品3", "price": 19.90},
{"id": 7, "name": "商品7", "price": 29.90},
]
# 按价格排序
data.sort(key=lambda d: d["price"])
print(data)
data: list[dict] = [
{"id": 6, "name": "商品1", "price": 49.90},
{"id": 2, "name": "商品2", "price": 39.90},
{"id": 4, "name": "商品4", "price": 89.90},
{"id": 3, "name": "商品3", "price": 19.90},
{"id": 7, "name": "商品7", "price": 29.90},
]
# 按ID排序
data.sort(key=lambda d: d["id"])
print(data)
"""列表.clear() 清空列表"""
data: list = ["A", "B"]
data.clear()
print(data) # [],清空成员,但是还是在内存中保留了列表的内容空间
# 列表.clear() 和 del 列表 的区别
data: list = ["A", "B"]
del data
# print(data) # del删除的是内存空间,所以一旦执行以后,连变量都没有了,后面使用需要重新赋值,否则报错
# 列表复制问题
data1: list = ["A", "B"]
data2: list = data1
print("data2=", data2) # ['A', 'B']
data2[1] = "C"
print("data2=", data2) # ['A', 'C']
print("data1=", data1) # ['A', 'C'],当data2改变了成员以后,data1也被改变了。
# 使用copy复制一个列表,可以在某种程度上解决上面的BUG,但是并不会彻底解决。
data1: list = ["A", "B"]
data2: list = data1.copy()
print("data2=", data2) # data2= ['A', 'B']
data2[1] = "C"
print("data2=", data2) # data2= ['A', 'C']
print("data1=", data1) # data1= ['A', 'B']
面试题:删除列表中的偶数成员:
data13: list = [2,5,2,2,2,2,4,5,6,6,1]
for item in data13:
if item % 2 == 0:
data13.remove(item)
print(data13) # [5, 2, 2, 5, 6, 1]
"""解决方法:把要删除的成员先找出来,然后再删除"""
data14: list = [2,5,2,2,2,2,4,5,6,6,1]
# 先声明一个列表,保存要删除的成员
data15: list = []
for i in data14:
if i %2 == 0:
data15.append(i)
# 根据被删除成员组成的列表,到原列表中进行删除
for i in data15:
data14.remove(i)
print(data14) # [5, 5, 1]
3.4 引用与传值¶
在使用list.copy()时,我们遇到了列表复制的问题,要彻底解决这个问题,我们需要了解变量赋值在Python中的本质:python中根本没有传值赋值,只有引用赋值。
在其他编程语言(go,java,php)中对一些基础数据类型使用=号赋值实际上就是开辟了一个新的内存空间,把等号右边的数据保存到新内存空间中,再把变量与新内存空间地址进行绑定,这就是传值赋值。
main.go,代码:
package main
import "fmt"
func main() {
var data1 int = 200;
var data2 int = 200;
var data3 int = data1;
fmt.Printf("变量'data1'的值:%d 内存地址:【%p】\n", data1, &data1);
fmt.Printf("变量'data2'的值:%d 内存地址:【%p】\n", data2, &data2);
fmt.Printf("变量'data3'的值:%d 内存地址:【%p】\n", data3, &data3);
}
Hello.java,代码:
public class Hello {
public static void main(String[] args){
int data1 = 200;
int data2 = 200;
int data3 = data1;
System.out.printf("变量'data1'的值:%d 哈希值:%s\n", data1, Integer.toHexString(System.identityHashCode(data1)));
System.out.printf("变量'data2'的值:%d 哈希值:%s\n", data2, Integer.toHexString(System.identityHashCode(data2)));
System.out.printf("变量'data3'的值:%d 哈希值:%s\n", data3, Integer.toHexString(System.identityHashCode(data3)));
}
}
但是在python中并不是这样的,Python中对变量进行赋值,就是把变量与内存地址进行绑定,而不是把变量与数据绑定,这叫引用赋值。
main.py,代码:
data1: int = 200
data2: int = 200
data3: int = data1
print(f"变量'data1'的值:{data1} 内存地址:{id(data1)}")
print(f"变量'data2'的值:{data2} 内存地址:{id(data2)}")
print(f"变量'data3'的值:{data3} 内存地址:{id(data3)}")
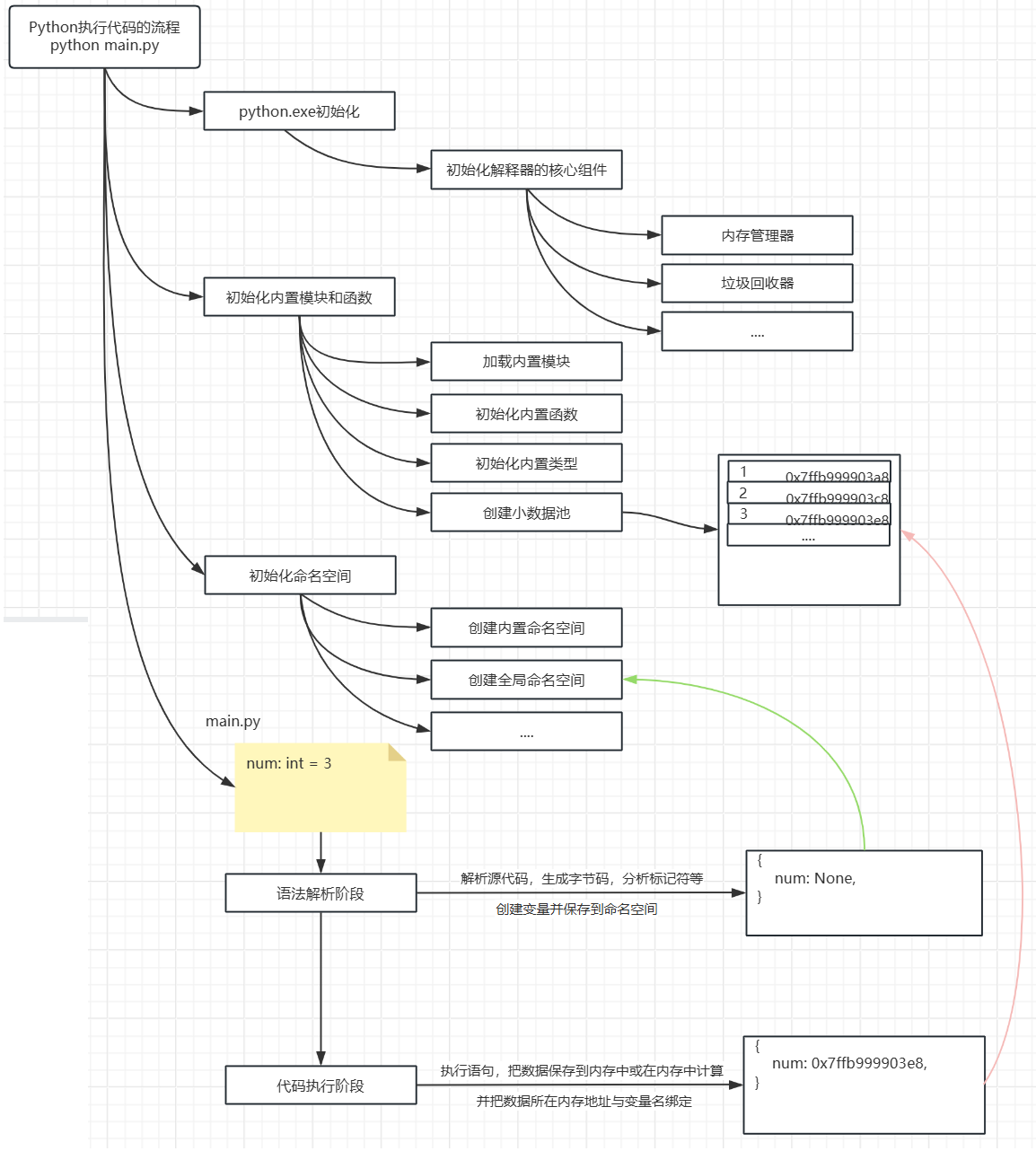
Python中的变量遇到=号赋值时的处理流程,如下:
print(3, id(3))
"""
Python中的变量遇到=号赋值时的处理流程
如果是首次赋值会先把变量名注册到命名空间中,(命名空间就是一个字典,其中键是变量名,值是变量名对应的数据所在的内存地址)
如果等号右边如果是另一个标记符,则直接把待赋值变量与该标记符指向的内存地址绑定。
然后判断等号右边的数据是否属于小数据范围:
如果是,则把变量名与小数据池中的该数据的内存地址绑定。小数据池中的数据是在Python解释器启动时就已经在内存中,不管程序中是否用到。
如果不是,则开辟一个新的内存空间。先把数据保存到内存空间中,再把变量名与该内存地址绑定。
"""
num: int = 3
print(num, id(num))
num1: int = num
print(num1, id(num))
print([], id([]))
num: list = []
print(num, id(num))
num1: list = num
print(num1, id(num))
这种引用赋值,就是多个变量同时与一个内存地址进行绑定,因此在部分特殊情况下会出现其中一个变量的值发生更改,会导致绑定该空间地址的其他变量的值也会跟着变化。这种特殊情况就是当多个变量同时指向同一个引用类型的容器数据(列表、字典、集合、元组在内,除了字符串)时。
# 列表
data1 = [1,"B", "C", "a+b"]
data2 = data1
data2.append(4)
print(id(data2), data2) # 2920473556352 [1, 'B', 'C', 'a+b', 4]
print(id(data1), data1) # 2920473556352 [1, 'B', 'C', 'a+b', 4]
# 字典
data1 = {"id":1, "title":"商品标题1"}
data2 = data1
data2["price"] = 99
print(id(data2), data2) # 2404875316608 {'id': 1, 'title': '商品标题1', 'price': 99}
print(id(data1), data1) # 2404875316608 {'id': 1, 'title': '商品标题1', 'price': 99}
# 集合
data1 = {1,"B", "C", "a+b"}
data2 = data1
data1.remove(1)
print(id(data2), data2) # 2697375590432 {"B", "C", "a+b"}
print(id(data1), data1) # 2697375590432 {"B", "C", "a+b"}
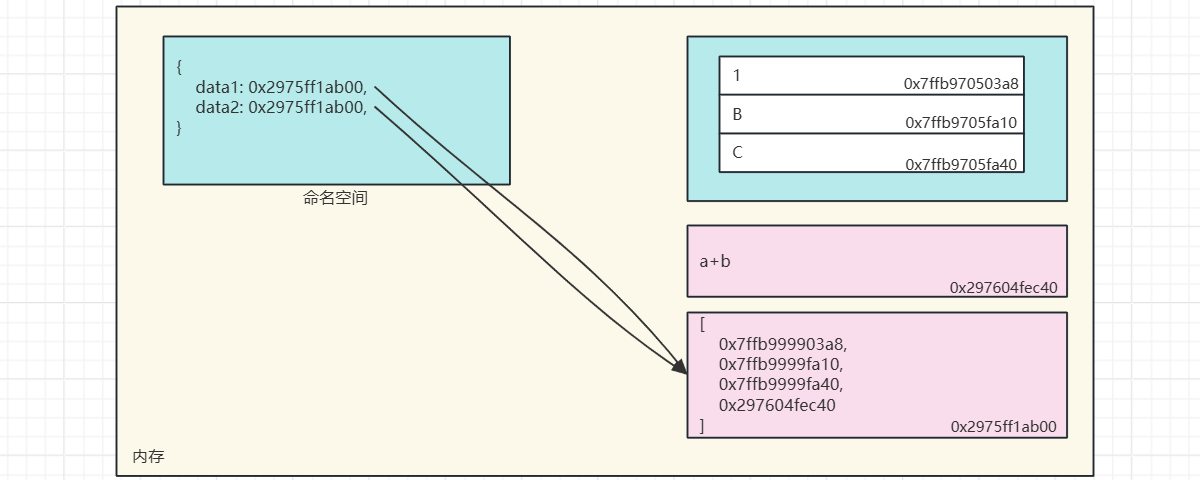
因为部分容器类型保存的实际上并非成员值,而是成员的地址引用,所以这些容器类型,被称为:引用类型,包括集合、列表、字典、元组。
3.5 浅拷贝与深拷贝¶
浅拷贝也叫浅复制,是编程语言中针对引用类型数据提供的一种表层复制数据的操作。
深拷贝也叫深复制,是编程语言中针对引用类型数据提供的一种深层复制数据的操作。
3.5.1 引用赋值对引用类型容器在浅拷贝时造成的问题¶
# 二级以上的列表[二维列表]
data1: list = [1,[4,5,6],[8,9]]
data2: list = data1.copy()
print(id(data2), data2) # 2085906686784 [1, [4, 5, 6], [8, 9]]
data2[0] = 2
data2[1].append(7)
print(id(data2), data2) # 2085906686784 [2, [4, 5, 6, 7], [8, 9]]
print(id(data1), data1) # 2085906687168 [1, [4, 5, 6, 7], [8, 9]]
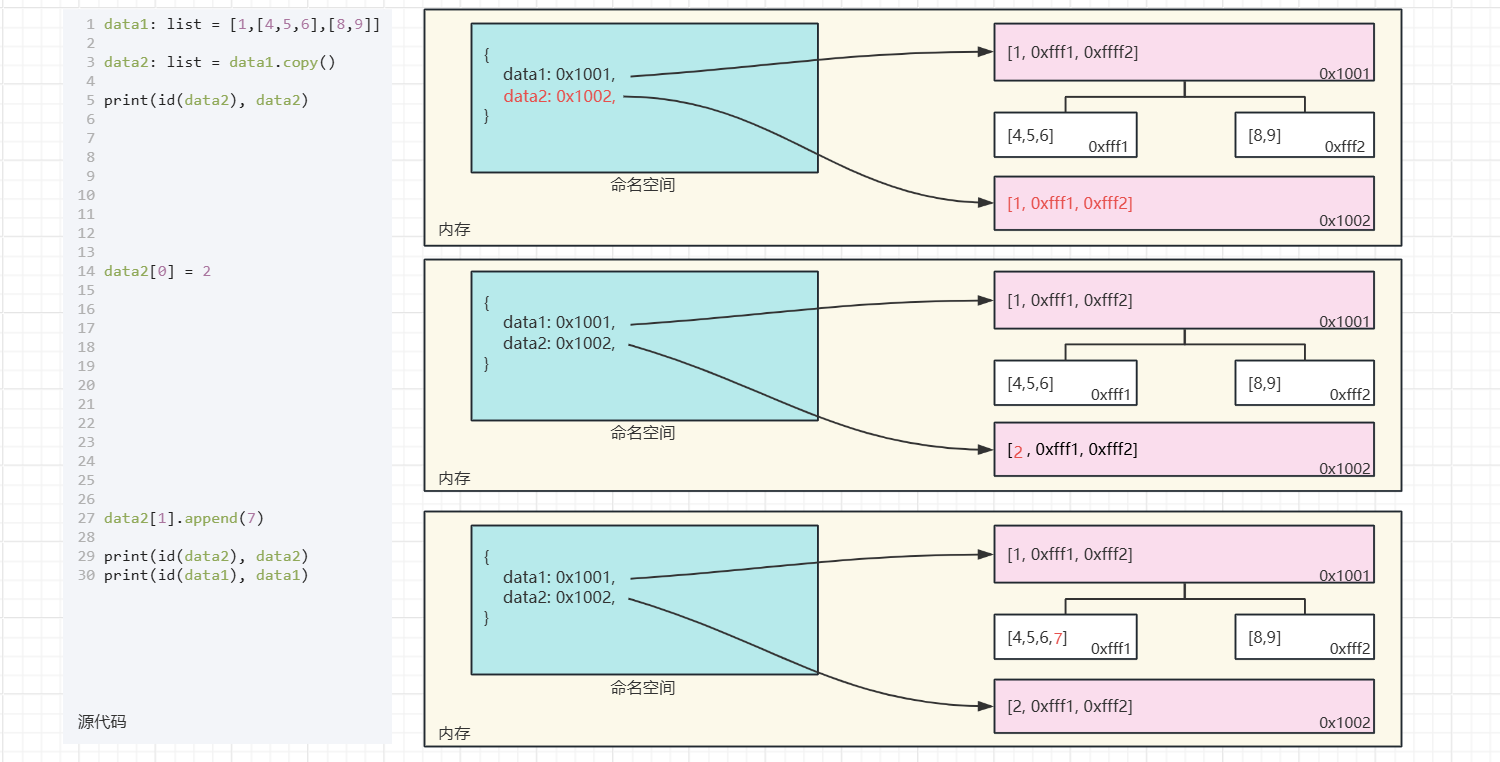
不仅列表,同样是引用类型容器的字典和集合、元组也存在这个问题,要解决这个问题就必须使用深拷贝来对二级以上的引用类型容器数据来进行复制。
在python中除了引用类型容器(列表,集合,字典、元组)本身提供的copy操作可以进行浅拷贝以外,还提供了内置模块copy给开发者进行数据的浅拷贝和深拷贝:
- 浅拷贝: 只拷贝外层列表,内层列表跟随原列表进行改变。copy.copy(变量) 或者 变量.copy()
- 深拷贝: 拷贝整个列表,内外列表都不跟随原列表进行改变。copy.deepcopy(listvar)
代码:
# 导入copy模块
import copy
# copy.copy(),用于浅拷贝
data1: list = [1 , 2 ,3 , 4 ]
data2: list = copy.copy(data1)
data2.append(6)
print(data1) # [1, 2, 3, 4]
# copy.deepcopy(),用于深拷贝
import copy
data1: list = [1,2,3,4,[5,6,7]]
data2: list = copy.deepcopy(data1)
data1[-1].append(19)
print(data2) # [1, 2, 3, 4, [5, 6, 7]]
# 二级以上容器需要使用深拷贝
data1: dict = {"a":[1,2,3,4],"b":{"c":1,"d":2}}
data2: dict = copy.deepcopy(data1)
data1["b"]["e"] = "大风车"
print(data1) # {'a': [1, 2, 3, 4], 'b': {'c': 1, 'd': 2, 'e': '大风车'}}
print(data2) # {'a': [1, 2, 3, 4], 'b': {'c': 1, 'd': 2}}
4. 元组进阶操作¶
因为元组属于不可变容器类型,一旦声明不可更改。因此并不具备成员的修改相关操作方法,仅支持如下部分函数与方法:
| 函数(必填参数) | 描述 |
|---|---|
| tuple(x) | 把x转换成元组 |
| len(x) | 获取元组的成员数量 |
| min(x) | 获取元组的最小值成员 |
| max(x) | 获取元组的最大值成员 |
| 方法(必填参数) | 描述 |
|---|---|
| tuple.count(x) | 统计成员x在元组中出现的次数,与字符串操作一样。 |
| tuple.index(x [, i, j]) | 从元组中找出成员x首次出现的索引位置,与字符串操作一样。 如果指定开始下标i或结束下标j则返回指定范围内的首次出现下标。 |
5. 集合进阶操作¶
5.1 集合常用函数与方法¶
| 函数(必填参数) | 描述 |
|---|---|
| set(x) | 把x转换成集合,去重。 |
| len(x) | 获取集合的成员数量 |
| min(x) | 获取集合的最小值成员 |
| max(x) | 获取集合的最大值成员 |
| 方法(必填参数,*多个参数) | 描述 |
|---|---|
| s.add(elem) | 为集合添加1个元素,others可以是任意不可变类型 |
| s.update(others) | 给集合添加多个元素,others必须是序列类型。 |
| s.clear() | 清空集合中的所有元素 |
| s.copy() | 浅拷贝一个集合,也支持使用copy模块 |
| s.remove() | 删除集合中指定的元素 |
| s.discard() | 删除集合中指定的元素 |
| s.pop() | 删除集合中的第一个元素,注意:并非随机。 |
| s.intersection(*others) | 获取多个集合的交集。不修改原集合。等价于 s & others |
| s.intersection_update(*others) | 获取多个集合的交集。修改原集合。等价于 s &= others |
| s.difference(*others) | 返回多个集合的差集。不修改原集合。等价于 s - others |
| s.difference_update(*others) | 返回多个集合的差集。修改原集合。等价于 s -= others |
| s.union(*others) | 返回多个集合的并集。等价于 s 丨 others |
| s.symmetric_difference(others) | 返回两个集合的对称差集,即互相不重复的元素的集合。不修改原集合。等价于s ^ others |
| s.symmetricdifferenceupdate(others) | 返回两个集合的对称差集,即互相不重复的元素的集合。修改原集合。等价于s ^= others |
| s.issubset(others) | 判断集合s是否为集合others的子集。等价于s<=others |
| s.issuperset() | 判断集合s是否为集合others的父集。等价于s>=others |
| s.isdisjoint() | 判断两个集合的成员是否不相交,如果是返回 True,否则返回 False。等价于 not (s == others) |
"""
add 新增一个成员,成员如果已经存在,则会被去重
update 新增多个成员
"""
data1: set = {"A", "B"}
data1.add("C")
print(data1) # {'C', 'A', 'B'}
# 添加已经存在的成员,会被去重掉,True等价于1,False等价于0
data1: set = {"A", "B", True}
data1.add(1)
print(data1) # {True, 'A', 'B'}
data1: set = {"A", "B"}
data1.update(["A", "F", "G"])
print(data1) # {'G', 'A', 'F', 'B'}
"""
clear 清空集合中所有的成员
del 使用关键字,删除空间对应的变量和数据
"""
data1: set = {"A", "B"}
data1.clear()
print(data1) # set() 空集
# # clear与del的区别。
# data2 = {"A", "B"}
# del data2
# print(data2) # 报错,NameError: name 'data2' is not defined ===> data2没有这个变量
"""集合.copy() 浅拷贝一个集合"""
data1: set = {"A", "B", "C", "D"}
data2: set = data1
print(data2) # {'C', 'A', 'D', 'B'}
"""
集合.remove() 删除成员,
集合.discard() 删除成员,
集合.pop() 随机删除一个成员,类似于抽奖
"""
# 删除不存在的成员不会报错
data1: set = {"A", "B", "C", "D"}
data1.discard("C")
print(data1) # {'A', 'B', 'D'}
# 删除不存在的成员会报错
data1: set = {"A", "B", "C", "D"}
data1.remove("C")
print(data1) # {'A', 'B', 'D'}
# 随机删除,如果集合为空,会报错
data1: set = {"A", "B", "C", "D"}
ret: str = data1.pop()
print(ret, data1) # C {'A', 'D', 'B'}
""" intersection() 交集 """
focus1: set = {"周杰伦", "赵丽颖", "黄渤", "王一博"}
focus2: set = {"张新成", "刘德华", "黄渤", "王一博", "赵丽颖"}
print(focus1 & focus2) # {'赵丽颖', '王一博', '黄渤'}
print(focus1.intersection(focus2)) # {'赵丽颖', '王一博', '黄渤'}
""" difference() 差集 """
focus1: set= {"周杰伦", "赵丽颖", "黄渤", "王一博"}
focus2: set = {"张新成", "刘德华", "王一博", "赵丽颖"}
print(focus1 - focus2) # {'周杰伦', '黄渤'}
print(focus1.difference(focus2)) # {'周杰伦', '黄渤'}
""" union() 并集 """
focus1: set = {"周杰伦", "赵丽颖", "黄渤", "王一博"}
focus2: set = {"张新成", "刘德华", "王一博", "赵丽颖"}
print(focus1 | focus2) # {'王一博', '张新成', '赵丽颖', '黄渤', '周杰伦', '刘德华'}
print(focus1.union(focus2)) # {'王一博', '张新成', '赵丽颖', '黄渤', '周杰伦', '刘德华'}
""" symmetric_difference() 返回两个集合中不重复的元素集合,即对称差集 """
focus1: set = {"周杰伦", "赵丽颖", "黄渤", "王一博"}
focus2: set = {"张新成", "刘德华", "王一博", "赵丽颖"}
print(focus1 ^ focus2) # {'张新成', '黄渤', '周杰伦', '刘德华'}
print(focus1.symmetric_difference(focus2)) # {'张新成', '黄渤', '周杰伦', '刘德华'}
"""
issuperset 判断一个集合是否是另一个集合的超集(父集,全集),等价于>=
issubset 判断一个集合是否是另一个集合的子集,等价于<=
isdisjoint 判断一个集合的成员是否与另一个集合完全不同,等价于not ==
"""
set1: set = {"A", "B", "C", "D"}
set2: set = {"A", "D"}
set3: set = {"B", "C"}
result: bool = set1.issuperset(set2)
print(result) # True
print(set1 >= set2) # True
result: bool = set2.issubset(set1)
print(result) # True
print(set2 <= set1) # True
# 判断是否完全不相交
result: bool = set2.isdisjoint(set3)
print(result) # True
6. 字典进阶操作¶
| 函数(必填参数) | 描述 |
|---|---|
| dict(x) | 把x转换成字典,要求数据的尺寸为nx2 |
| len(x) | 获取字典的键值对成员数量 |
| min(x) | 获取字典的最小的键 |
| max(x) | 获取元组的最大的键 |
| 方法(必填参数,选填参数=默认值[, 选填参数, ...]) | 函数及描述 |
|---|---|
| dict.clear() | 清空字典内所有元素 |
| dict.copy() | 复制字典 |
| dict.fromkeys(iterable, value=None) | 创建新字典,以序列iterable中元素做字典的键,value为对应的初始值。 |
| dict.get(key, default=None) | 返回指定键的值,如果键不存在则返回 default 设置的默认值 |
| dict.setdefault(key, default=None) | 获取指定键的值,如果键不存在,将会添加键并将值设为default的值。 |
| dict.keys() | 返回字典所有的键组成的视图对象。 |
| dict.values() | 返回字典所有的值组成的视图对象。 |
| dict.items() | 返回字典所有的键值对组成的视图对象。 |
| dict.update(dict2) | 合并字典。等价于dict 丨=dict2 |
| dict.pop(key[,default]) | 删除字典给定键 key 所对应的值,返回值为被删除的值。key值必须给出。 否则,返回default值。 |
| popitem() | 返回并删除字典中的最后一对键和值。 |
"""dict(x) 把尺寸为nx2的容器类型转换成字典"""
data1: list = ["A1", "B2"]
print(dict(data1)) # {'A': '1', 'B': '2'}
data2: list = [("A", 1), ("B",2), "C3"]
print(dict(data2)) # {'A': 1, 'B': 2, 'C': '3'}
data3: tuple = ("A1", ["B", 1])
print(dict(data3)) # {'A': '1', 'B': 1}
data4: set = {"A1", "B1"}
print(dict(data4)) # {'B': '1', 'A': '1'}
"""len() 获取字典中键值对的数量,即字典长度"""
data5: dict = {'A': 1, 'B': 2, 'C': '3'}
print(len(data5)) # 3
"""
max() 获取字典中最大的键
min() 获取字典中最小的键
"""
data6: dict = {"A":10, "B": 2}
print(max(data6)) # B
print(min(data6)) # A
"""字典.clear() 清空字典所有成员"""
data1: dict = {"top": "吕布", "mid": "甄姬", "adc": "鲁班"}
data1.clear()
print(data1)
"""字典.copy() 复制字典"""
data2: dict = {"top": "吕布", "mid": "甄姬", "adc": "鲁班"}
data3: dict = data2.copy()
print(data2, id(data2))
print(data3, id(data3))
"""字典fromkeys() 使用一组键和默认值创建字典"""
data4: dict = {}.fromkeys(["a", "b"], None)
print(dictvar2) # {'a': None, 'b': None}
"""get() 通过键获取值,若没有该键可设置默认值,预防报错"""
data5: dict = {"top": "吕布", "mid": "甄姬", "adc": "鲁班"}
print(data5.get("mid"))
print(data5.get("sup", None))
"""字典.setdefault(default=None) 获取指定键的值,如果不存在,则给字典新增default默认值"""
data6: dict = {"top": "吕布", "mid": "甄姬", "adc": "鲁班"}
role1: str = data6.setdefault('top')
print(role1, data6) # 吕布 {'top': '吕布', 'mid': '甄姬', 'adc': '鲁班'}
role2: str = data6.setdefault('sup', '蔡文姬')
print(role2, data6) # 蔡文姬 {'top': '吕布', 'mid': '甄姬', 'adc': '鲁班', 'sup': '蔡文姬'}
"""
keys() 将字典的键组成视图对象
values() 将字典的值组成视图对象
items() 将字典转换成nx2的二级容器视图对象 [(key, value), (key, value), ....]
"""
data7: dict = {"top": "吕布", "mid": "甄姬", "adc": "鲁班"}
print(data7.keys()) # dict_keys(['top', 'mid', 'adc'])
print(data7.values()) # dict_values(['吕布', '甄姬', '鲁班'])
print(data7.items()) # dict_items([('top', '吕布'), ('mid', '甄姬'), ('adc', '鲁班')])
for key, value in data7.items():
print(f"{key}: {value}")
# 视图对象是一种不能用于比较的只读引用对象,当字典该发生改变时,视图对象的值也会随之改变。
from typing import ItemsView
data8: dict = {"top": "吕布", "mid": "甄姬", "adc": "鲁班"}
data9: ItemsView = data8.items()
data8['top'] = "花木兰"
print(data9) # dict_items([('top', '花木兰'), ('mid', '甄姬'), ('adc', '鲁班')])
"""update() 字典合并,批量更新,重复则覆盖,等价于 |= """
data10: dict = {"top": "吕布", "mid": "甄姬", "adc": "鲁班"}
data11: dict = {"jun": "李白", "sup": "蔡文姬"}
data10.update(data11)
print(data10) # {'top': '吕布', 'mid': '甄姬', 'adc': '鲁班', 'jun': '李白', 'sup': '蔡文姬'}
data12: dict = {"top": "吕布", "mid": "甄姬", "adc": "鲁班"}
data13: dict = {"jun": "李白", "sup": "蔡文姬"}
data12 |= data13
print(data12) # {'top': '吕布', 'mid': '甄姬', 'adc': '鲁班', 'jun': '李白', 'sup': '蔡文姬'}
"""
pop(key, default=None) 根据键删除对应的键值对 (若没有该键可设置默认值,预防报错)
popitem() 按字典书写顺序,获取最后一个键值对并从字典中删除,如果空字典则报错。
"""
data14: dict = {"top": "吕布", "mid": "甄姬", "adc": "鲁班"}
res: str = data14.pop("top")
print(res, data14) # 吕布 {'mid': '甄姬', 'adc': '鲁班'}
res: str | None = data14.pop("sup", None)
print(res) # None
data15: dict = {"top": "吕布", "mid": "甄姬", "adc": "鲁班"}
res: tuple = data15.popitem()
print(res, data15) # ('adc', '鲁班') {'top': '吕布', 'mid': '甄姬'}
7. 类型注解进阶¶
PEP585规范中,针对PEP484规范提供了更多简便灵活的注解写法,当然与PEP484规范一样,这些并非语法,而是推荐规范,遵循以后全看个人。
# 任意类型,相当于Any
data0: ... = "Hello Moluo"
# 多选1类型
data1: str | None = None
data2: int | float = 3.5
# 列表,统一指定成员类型
data3: list[int] = [0, 1, 2]
data4: list[str] = ["A", "B", "C"]
data5: list[bool | int | str] = [True, False, 100, "ABC"]
# 元组:指定各个成员类型
data6: tuple[int, int, int] = (1,2,3)
data7: tuple[int, bool, str] = (1,True, "小明")
data8: tuple[int, bool, str, ...] = (1, True, "小明", 399, "Hello world", False, False, False)
# 集合
data9: set[str] ={"A", "B", "C"}
# 字典,指定键值的类型
data10: dict[str, str] = {"name": "小明", "created_time": "2025-03-17 09:00:00"}
data11: dict[str, str | int] = {"id":1, "name": "小明", "created_time": "2025-03-17 09:00:00"}
# 多级容器【多维列表、多维元组、多维字典等等】
data12: list[dict[str, int | str]] = [
{"id": 1, "name": "商品1", "price": 100},
{"id": 2, "name": "商品2", "price": 110},
]
8. 案例:学生信息管理系统(终端版本)¶
需求:在终端下提供一个保存学生信息的程序,能查看/修改/删除/添加学生数据,能退出管理系统。
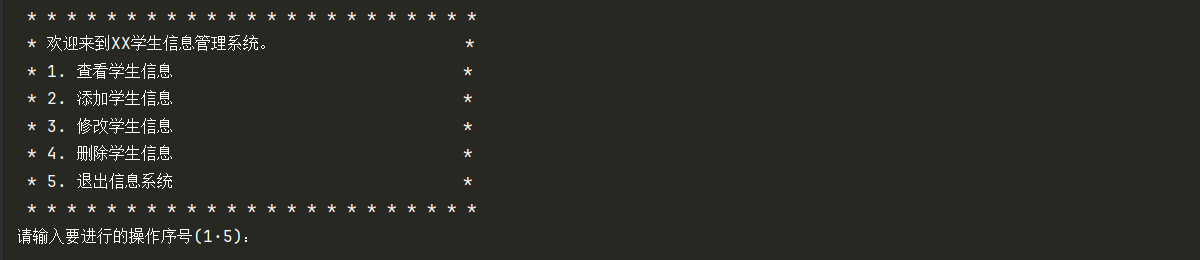
系统欢迎界面:
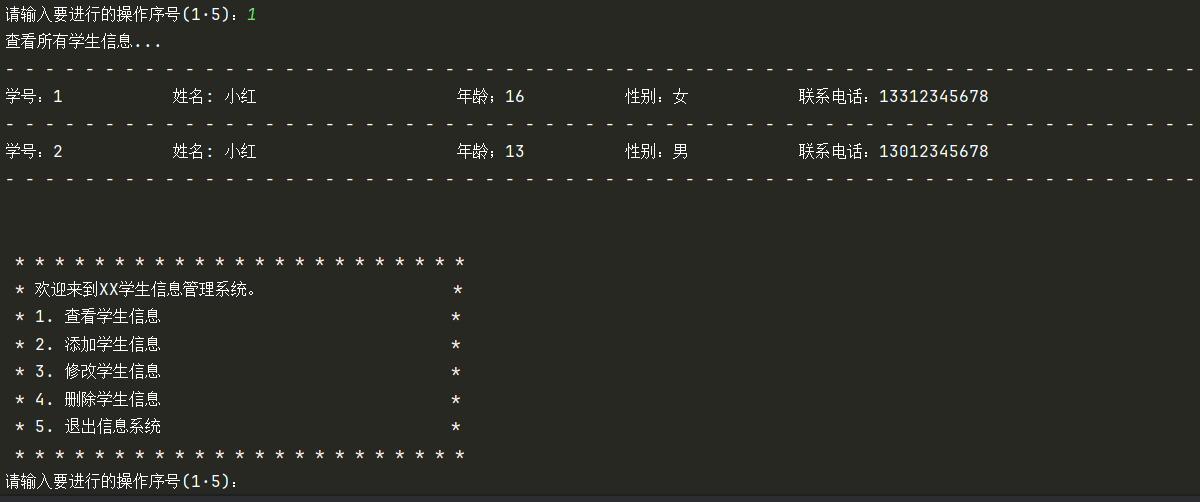
查看学生信息界面:
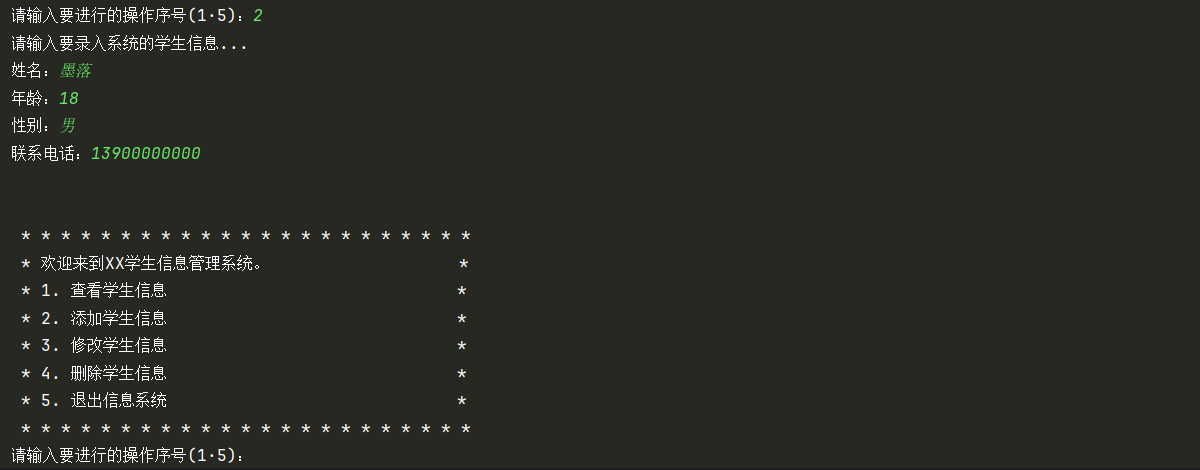
添加学生信息界面:
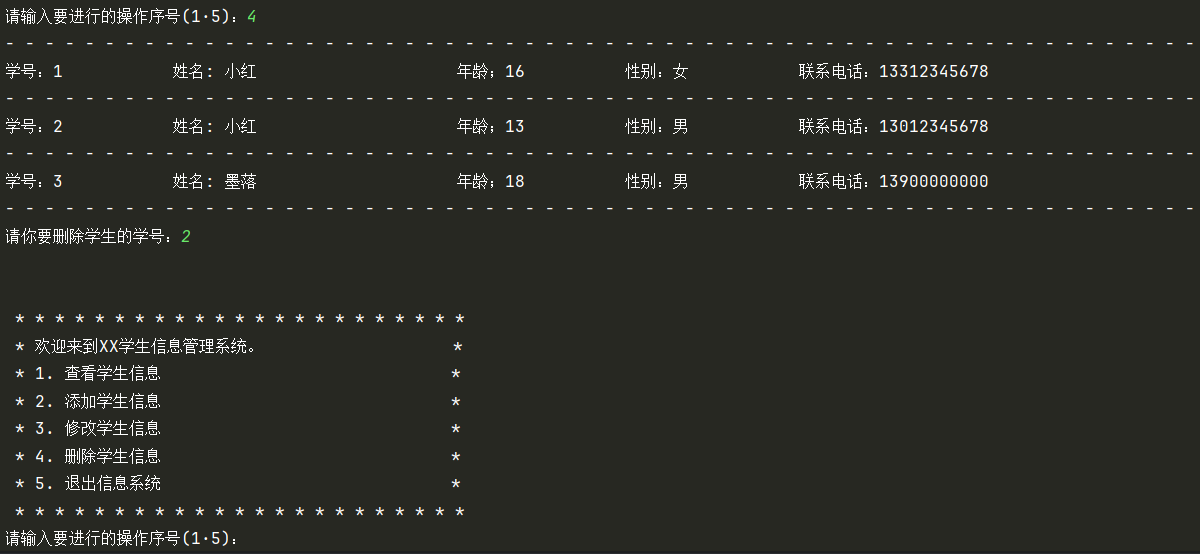
删除学生信息界面:
退出系统界面:

演示代码:
welcome: str = "欢迎来到xx学生信息管理系统。"
menu_list: list[str] = [
"1. 查看学生信息",
"2. 添加学生信息",
"3. 修改学生信息",
"4. 删除学生信息",
"5. 退出信息系统",
]
question: str = "请输入要进行的操作序号(1-5):"
student_list: list[dict[str,str|int]] = [
{"name": "小红", "age": 16, "gender": "女", "phone": "13312345567"},
{"name": "小红", "age": 13, "gender": "男", "phone": "13312345567"},
]
while True:
print("* " * 32)
print(f"* {welcome: <52}*")
for menu in menu_list:
print(f"* {menu: <56}*")
print("* " * 32)
answer: str = input(question)
match answer:
case "1":
print("查看所有学生信息...")
print("- " * 56)
for index, student in enumerate(student_list):
if student == {}:
continue
print(f"{f"学号:{index+1}": <10} {f"姓名:{student['name']}": <14} {f"年龄:{student['age']}": <14} {f"性别:{student['gender']}": <10} 联系电话:{student['phone']}")
print("- " * 56)
case "2":
print("请输入要录入系统的学生信息...")
name: str = input("姓名:")
age: int = int(input("年龄:"))
gender: str = input("性别:")
phone: str = input("联系电话:")
student_list.append({"name": name, "age": age, "gender": gender, "phone": phone})
case "3":
print("更新学生信息...")
print("- " * 56)
for index, student in enumerate(student_list):
if student == {}:
continue
print(f"{f"学号:{index+1}": <10} {f"姓名:{student['name']}": <14} {f"年龄:{student['age']}": <14} {f"性别:{student['gender']}": <10} 联系电话:{student['phone']}")
print("- " * 56)
number: int = int(input("请输入要更新的学生序号:"))
student: dict = student_list[number-1]
name: str = input(f"姓名({student['name']}),如果不填写则默认不修改:")
age: str = input(f"年龄({student['age']}),如果不填写则默认不修改:")
gender: str = input(f"性别({student['gender']}),如果不填写则默认不修改:")
phone: str = input(f"联系电话({student['phone']}),如果不填写则默认不修改:")
if len(name) > 0:
student["name"] = name
if len(age) > 0:
student["age"] = age
if len(gender) > 0:
student["gender"] = gender
if len(phone) > 0:
student["phone"] = phone
case "4":
print("删除学生信息...")
print("- " * 56)
for index, student in enumerate(student_list):
if student == {}:
continue
print(f"{f"学号:{index+1}": <10} {f"姓名:{student['name']}": <14} {f"年龄:{student['age']}": <14} {f"性别:{student['gender']}": <10} 联系电话:{student['phone']}")
print("- " * 56)
number: int = int(input("请输入要删除的学生序号:"))
# 因为我们使用了列表的下标作为学号,因此不能直接通过删除成员来完成学生信息删除操作,而是应该替换成空字典来完成虚拟的删除
student_list[number-1] = {}
case "5":
print("成功退出信息系统...s")
break
print()
print()