面向对象高级¶
1. 内置对象的属性¶
在python中,万物皆为对象,所以对象虽然是类创建的。但是类本身存在于内存中,类本身也是一个对象,一般称之为类对象。因此我们之前学习过程中,所创建的类属性和类方法,就是类对象本身的方法和属性,除此之外,类本身也存在着一些内置的属性。
| 属性 | 类型 | 描述 |
|---|---|---|
__dict__ |
类 | 返回类的类方法、实例方法、静态方法和类属性组成字典 |
__doc__ |
类 | 类的说明文档 |
__name__ |
类 | 类名 |
__module__ |
类 | 类定义所在的模块,__main__表示当前主模块 |
__base__ |
类 | 类继承的第一个父类 |
__bases__ |
类 | 类的所有父类构成元素(注意:仅仅是父类,不是祖先类) |
__slots__ |
类 | 限制类实例对象的属性,不允许外界新增__slots__成员以外的实例属性 |
__dict__ |
对象 | 返回对象的属性组成的字典 |
__class__ |
对象 | 返回对象的类 |
__module__ |
对象 | 对象所在的模块 |
__doc__ |
对象 | 对象所属类的说明文档 |
代码:
class A(object):
pass
class B(object):
pass
class C(A, B):
"""C类说明文档"""
id = 10
def __init__(self, name ,age):
self.name = name
self.age = age
def abc(self):
return "abc"
@classmethod
def met(cls):
return "mety"
c =C("小明", 16)
print("类.__dict__:", C.__dict__)
print("类.__doc__:", C.__doc__)
print("类.__name__:", C.__name__)
print("类.__module__:", C.__module__)
print("类.__base__:", C.__base__)
print("类.__bases__:", C.__bases__)
print("对象.__dict__:", c.__dict__)
print("对象.__class__:", c.__class__)
print("对象.__module__:", c.__module__)
print("对象.__doc__:", c.__doc__)
使用__slots__限制类的外界对实例对象的实例属性随意动态增加。
class Person(object):
__slots__ = ["name", "age"]
def __init__(self, name, age):
self.name = name
self.age = age
xm = Person("小明", 18)
print(xm.name, xm.age)
xm.score = 96 # 此处,会报错,因为score属性并没有在__slots__中注册
2. 反射机制¶
反射(reflection)这个术语在很多面向对象编程语言中都存在,并且被大量使用,也叫自省。
那什么是反射?反射主要是指程序通过字符串的形式操作对象中(查找/获取/删除/添加)的成员,以达到访问、检测和修改对象本身状态或行为的一种能力,在python中一切皆对象(类,实例,模块等都是对象),那么我们就可以通过反射的形式操作对象相关的属性。
开发中,在不清楚方法或属性是否存在于指定对象中时,可以通过反射机制来查找或操作对象的属性或方法。对象的反射查找路径与类的继承查找路径一样,都是基于MRO。Python中的反射主要有下面几个方法:
| 方法 | 描述 |
|---|---|
| getattr(object,name[,default]) | 获取object对象的name属性的值,如果不存在,则返回默认值default,如果没有default,则抛出异常 |
| setattr(object,name,value) | 设置object对象的name属性的值,如name属性存在则覆盖,name属性不存在则新增name属性 |
| hasaattr(object,name) | 判断object对象的name属性是否存在,返回布尔值 |
| delattr(object,name) | 删除object对象的name属性 |
除了上面几个以外,我们前面学习的type、isinstance、dir、callable等都是基于对象反射机制实现的。
2.1 实例对象¶
class Person(object):
"""人类"""
def __init__(self,name, age):
self.name = name
self.age = age
def introduction(self):
"""自我介绍"""
print(f"我叫{self.name}")
xm = Person("小明", 18)
# hasattr 判断对象中是否存在 属性
print(hasattr(xm, "name")) # True,存在name变量
print(hasattr(xm, "introduction")) # True,存在introduction方法
print(hasattr(xm, "sex")) # False,不存在sex方法或变量
# getattr 获取对象中的属性
f1 = getattr(xm, 'introduction') # f1 = xm.introduction
f1() # 我叫小明
# 如果xm中不存在属性,则会报错,可以设置default,返回None、False、True
f2 = getattr(xm, 'sex', None)
print(f2) # None
# setattr 为对象设置属性
setattr(xm, 'sex', True) # 等同于 xm.sex = True
print(xm.__dict__) # {'name': '小明', 'age': 18, 'sex': True}
# delattr 删除对象属性
delattr(xm, 'age') # 等同于 del xm.age
print(xm.__dict__) # {'name': '小明', 'sex': True}
2.2 类对象¶
class Person(object):
leg_length = 2
eye_length = 2
@classmethod
def info(cls):
print(f"人类有{cls.leg_length}条腿,{cls.eye_length}只眼睛")
@classmethod
def speak(cls, message):
return f"说话:{message}"
# 获取类属性
print(getattr(Person, 'leg_length')) # 2, 存在city方法
# 获取类的方法
speak = getattr(Person, "speak")
print(speak("你好!!!")) # 说话:你好!!!
# 设置类属性
setattr(Person, 'max_age', 150)
print(Person.max_age) # 150
# 设置类方法
def info(cls, message):
return f"{message}:人类有{cls.leg_length}条腿,{cls.eye_length}只眼睛"
setattr(Person, 'info', info)
print(Person.info(Person, "自我介紹")) # 说话:hello
# 刪除类属性
delattr(Person, "max_age")
print(Person.__dict__)
2.3 模块对象¶
import random
# random是一个内置模块,同时python运行时,也是一个模块对象
print(random) # <module 'random' from 'C:\\ProgramData\\Miniconda3\\envs\\djdemo\\lib\\random.py'>
# 读取属性
print(getattr(random,"Random")) # <module 'random' from 'C:\\ProgramData\\Miniconda3\\envs\\djdemo\\lib\\random.py'>
randint = getattr(random, 'randint')
# 判断是否调用
if callable(randint):
print(randint(1, 100))
# 设置属性
setattr(random, 'name', '伪随机数模块')
print(random.name) # 伪随机数模块
# 反射当前模块的成员
import sys
module = sys.modules[__name__]
print(module.randint(10,20))
# 反射指定路径的模块
# 方式1:__import__
module = __import__('http.client', fromlist=True)
print(module.OK)
# 方式2:importlib.import_module
import importlib
module = importlib.import_module('http.client')
print(module.OK)
3. 异常处理进阶¶
在python中,异常处理除了我们前面学习的基础操作以外,还可以自定义异常或同时捕获多个异常。
而自定义异常则需要自定义异常类即可。
class CustomException(Exception):
def __init__(self, message):
self.message = message
try:
raise CustomException("抛出一个自定义异常")
except CustomException as e:
print(e.message)
4. 元类¶
我们前面提到python中万物皆对象,类也属于对象,还说到对象是由类实例化得到的。那么,问题来了,类也是对象,那么产生类的又是谁呢?那就是类的类了,也就是元类(metaclass),元类的主要作用是为了控制类的创建行为。
元类就是用来实例化类的基类,关系如下:

4.1 类声明的本质¶
type是Python的一个内建元类,用来直接控制生成类(为了方便大家理解,后面type类创建的类,改叫类对象),在python当中任何class定义的类其实都是type类实例化的结果。
在Python当中,使用class关键字创建一个类的本质其实在python解释器内部会自动转化为使用type元类实例化一个类对象。
class Person(object):
country = 'China'
def __init__(self,name, age):
self.name = name
self.age = age
def introduction(self):
print(f"我叫{self.name},今年{self.age}岁!")
xm = Person("小明", 17)
print(xm.country)
xm.introduction()
对元类type进行实例化,依次传入类名(实际上就是__name__),继承的父类元组(实际上就是__bases__),类的属性方法字典(实际上就是__bases__)这三个参数即可。
country = 'China'
def __init__(self, name, age):
self.name = name
self.age = age
def introduction(self):
print(f"我叫{self.name},今年{self.age}岁!")
Person = type('Person', (object,), {
'country': country,
'__init__': __init__,
'introduction': introduction})
xm = Person("小明", 17)
print(xm.country)
xm.introduction()
上面的代码,细心点的同学就会发现,使用type类创建的类对象,实际上已经参数化了,也就是不再需要我们写固定的源代码来创建类了。这样的话,我们就可以在开发中基于不同的业务,不同的场景,随时随地的动态创建类对象,而不再需要提前声明。
例如:我们需要渊源不断的生产不同类型的汽车,那么不使用元类的话,代码如下:
# 因为有不同类型的汽车要求,所以我们需要提前声明各种类型的汽车类
class SUV(object):
"""越野车"""
name = "SUV"
def run(cls):
return f"{cls.name}汽车在飞奔..."
class Sports(object):
"""跑车"""
name = "Sports"
def run(cls):
return f"{cls.name}汽车在飞奔..."
def car_factory(name):
if name == 'SUV':
return SUV # 返回的是类,不是类的实例
else:
return Sports
Car = car_factory('SUV')
print(Car) # 函数返回的是类,不是类的实例
print(Car().run()) # 你可以通过这个类创建类实例,也就是对象
Car = car_factory('Sports')
print(Car)
print(Car().run())
上面的代码会存在问题,如果后面需要生产其他类型的汽车,则需要不断的提前声明更多不同类型的汽车类,而且每增加一个种类的汽车,都要对car_factory函数的代码进行修改。所以需要优化,而使用type元类动态创建类对象就可以达到我们所想要的目的。
def run(cls):
return f"{cls.name}汽车在飞奔..."
# 下面car_factory函数中只传入一个参数name仅为举例子,实际上开发中,可以传递更多用于定制动态创建类对象的参数。
def car_factory(name):
return type(name, (object, ), {
"name": name,
"run": run
})
Car = car_factory('SUV')
print(Car) # 函数返回的是类,不是类的实例
print(Car().run()) # 你可以通过这个类创建实例对象
Car = car_factory('Sports')
print(Car)
print(Car().run())
Car = car_factory("Pickup")
print(Car)
print(Car().run())
4.2 自定义元类¶
Python中除了内置的type元类以外,用户也是可以自定义元类的,只要继承type类即可。只有继承了type类才能称之为一个元类,否则就是一个普通的自定义类,自定义元类可以控制类的产生过程。
例如,我们前面学习过的单例模式,也可以基于元类来实现,而且基于元类写法,可以很方便的给不同的类设置单例模式。
class Singleton(type):
def __init__(self, *args, **kwargs):
print("__init__")
self.__instance = None
super().__init__(*args, **kwargs)
def __call__(self, *args, **kwargs):
print("__call__")
if self.__instance is None:
self.__instance = super().__call__(*args, **kwargs)
return self.__instance
class Log(metaclass=Singleton):
pass
logger1 = Log()
logger2 = Log()
print(Log.__dict__) # {'__module__': '__main__', '__metaclass__': <class '__main__.Singleton'>, '__dict__': <attribute '__dict__' of 'Log' objects>, '__weakref__': <attribute '__weakref__' of 'Log' objects>, '__doc__': None}
print(logger1 is logger2) # True
当然,除了上面的单例模式的应用以外,开发中还可以基于元类的特点,保证代码规范问题。例如要求程序中设计的类,类名必须首字母大写,而且必须有类的文档说明和所有公有方法的文档说明,不能为空。
class Meta(type):
def __init__(self, cls_name, cls_bases, cls_dict):
if cls_name != cls_name.title():
raise TypeError(f"类名必须首字母大写!")
if '__doc__' not in cls_dict or len(cls_dict['__doc__'].strip()) == 0:
raise TypeError(f"类:{cls_name} 必须有文档说明,不能为空!")
for key, value in cls_dict.items():
if key.startswith('__'):
continue
if not callable(value):
continue
if not value.__doc__ or len(value.__doc__.strip()) == 0:
raise TypeError(f"公有方法:{key} 必须有文档说明,不能为空!")
super().__init__(cls_name, cls_bases, cls_dict) # 重用父类的功能.
class Person(object, metaclass=Meta):
"""元类"""
country = 'China'
def __init__(self, name, age):
self.name = name
self.age = age
def introduction(self):
"""自我介绍"""
return f"我叫{self.name},今年{self.age}岁了"
4.3 蛋生鸡和鸡生蛋问题¶
在工作面试时,经常有面试官会问到一个问题:object是所有类的基类,而所有类都是元类type创建的,但type本质上还是类,那么object就是type的基类。那么你怎么理解两者的关系?
实际上 object 和 type 在 CPython 解释器底层中都是用c代码同时生成的,并非在Python创建的,所以并没有先后关系,并且它们的依赖关系也是通过底层C代码由官方人员人为规定的。
在实际开发中,一般用不上元类,但是在很多底层模块或第三方模块中大量运用了元类,当我们如果深入学习这些模块的源码时,如果不了解元类的话,是很难理解的。换句话说,当我们以后想要实现一些自己的中大型应用程序或编写底层模块时,元类将是我们不能不触碰的一块内容。
5. 抽象类¶
在面向对象编程中,抽象类(Abstract Class)就是只能被子类继承,而不能直接实例化对象的特殊类,这种类用于定义子类的代码编写规范和编写子类中公有的具体方法,与抽象类相似的还有接口类(Interface Class),接口类仅用于定义子类的代码编写规范,没有具体的实现方法代码。
在其他的面向对象编程语言中,抽象类与接口类都是作为一种语法存在,而Python中不管抽象类还是接口类在原生语法中都是不提供的。如果要在Python中实现抽象类,可以使用内置模块abc模块(Abstract Base Classes,译作:抽象类基类模块)基于元类来实现,而接口类,则因为在Python中类本身支持多继承所以并没有提供任何内置模块,如果要实现接口类效果,可以基于第三方模块zope.interface来实现。
为什么要使用抽象类?其目的就是为了规范代码的编写。
举个例子,开发中一般程序里面如果有支付功能,因为支付需要到第三方支付平台申请操作权限(也就是申请支付接口)需要一定的资质与时间,所以我们往往在开发前期只会做少数几种支付方式,甚至是一种支付方式,先把用户支付的整个过程代码完成,但是随着后面的不断开发,甚至项目放在了公网上进行运营时,我们极有可能会继续开发更多不同银行或不同支付平台的支付流程,但此时,我们在项目中提供给用户支付的流程代码已经固定了,那么怎么保证在几个月后或者几年后所写的不同支付方式的代码依然能对接这个已经固定的代码流程呢?这时候,就需要限制后来的开发人员所编写的新的支付流程代码格式要与之前统一了。怎么限制?使用抽象类或接口类。
注意:不同于Java等语言有明确的语法区分接口类和抽象类,在Python里两者只是概念上的区别,本质是一样的。
5.1 抽象类的定义¶
上面提到,Python中的abc内置模块提供了定义抽象类的操作。
文档:https://docs.python.org/zh-cn/3.9/library/abc.html
| 操作 | 说明 |
|---|---|
| @abc.abstractmethod | 标记一个方法为抽象方法,只定义方法名和参数,而要求子类继承时必须实现具体代码,是个装饰器。 |
| abc.ABC | 定义当前类为抽象类,本质上就是一个元类 |
| abc.ABCMate | 定义当前类为抽象元类,abc.ABC的父级元类。Python3.4以后建议使用上面的abc.ABC。 |
代码:
import abc
class 抽象类名(abc.ABC):
"""
通过继承abc.ABC 实现抽象类
"""
# 抽象类中可以有0或多个抽象方法
@abc.abstractmethod
def 抽象方法名(self, *args, **kwargs):
pass
# 抽象类中也可以有0或多个具体方法
def 具体方法名(self, *args, **kwargs):
print(f"这里是具体方法的实现代码,{self.__name__}")
# 抽象类中也可以定义0或多个抽象类方法或抽象静态方法
@classmethod
@abc.abstractmethod
def 抽象类方法名(cls, *args, **kwargs):
pass
@staticmethod
@abc.abstractmethod
def 抽象静态方法名(*args, **kwargs):
pass
# 抽象类中也可以有0或多个抽象属性
@property
@abc.abstractmethod
def 抽象属性名(self):
pass
@抽象属性名.setter
@abc.abstractmethod
def 抽象属性名(self, value):
pass
注意,不同版本的Python在定义抽象类时写法有出入,但是本质上不变的,上面是Python3.4以上版本写法。
Python3.4以下的Python3版本:
class 抽象类名(object, metaclass=abc.ABCMeta):
@abc.abstractmethod
def 抽象类方法名(self, *args, **kwargs):
pass
Python2版本:
5.2 抽象类的使用¶
判断一个类是否是继承了抽象类,也就是判断一个类是否是指定类的子类,可以使用issubclass来判断。
import abc
# metaclass = abc.ABC 就是在定义抽象类,实际上是设置当前类为元类
# 所以abc模块实际上是基于元类限制类的创建这种方式来达到抽象类的效果
class Payment(abc.ABC):
# 使用abc.abstractmethod 装饰器定义抽象方法
@abc.abstractmethod
def pay(self, money):
"""发起支付,请求第三方支付平台进行转账"""
pass
@abc.abstractmethod
def result_handle(self):
"""支付结果处理,获取第三方支付平台的转账结果"""
pass
class AliPay(Payment):
"""支付宝"""
def pay(self, money):
"""发起支付,请求第三方支付平台进行转账"""
print("支付宝支付%d元" % money)
# def result_handle(self):
# """支付结果处理,获取第三方支付平台的转账结果"""
# print("支付宝转账成功!")
payment = AliPay()
# 判断AliPay是否是Payment的子类
print(issubclass(AliPay, Payment))
6. 设计模式¶
设计模式(Design pattern),就是前人针对特定场景特定问题所总结出来的解决方案。设计模式不是语法规定,而是一套用来提高代码复用性、维护性、可读性、稳健性以及安全性的解决方案。1995 年,GoF(Gang of Four,四人组/四人帮)合作出版了《设计模式:可复用面向对象软件的基础》一书,共收录了 23 种设计模式,人称「GoF设计模式」)。这 23 种设计模式的本质是对面向对象设计原则五大原则的实际运用,是对面向对象的封装、继承和多态的充分理解。
| 范围/目的 | 创建型模式 | 结构型模式 | 行为型模式 |
|---|---|---|---|
| 类模式 | 工厂(Factory Pattern) | 适配器(Adapter Pattern) | 模板方法(Template Method Pattern) 解释器(Interpreter Pattern) |
| 对象模式 | 单例(Singleton Pattern) 原型(Prototype Pattern) 抽象工厂(Abstract Factory Pattern) 建造者(Builder Pattern) |
代理(Proxy Pattern) 适配器(Adapter Pattern) 桥接(Bridge Pattern) 装饰器(Decorator Pattern) 外观(Facade Pattern) 享元(Flyweight Pattern) 组合(Composite Pattern) 生产者与消费者模式(producer & curstom Pattern) |
策略(Strategy Pattern) 命令(Command Pattern) 职责链(Chain of Responsibility Pattern) 状态(State Pattern) 观察者(Observer Pattern) 中介者(Mediator Pattern) 迭代器(Iterator Pattern) 访问者(Visitor Pattern) 备忘录(Memento Pattern) |
除了23种GoF设计模式,还有其他的常用设计模式,如:MVC模式(Model-View-Controller Pattern)、链式模式(Chain Pattern)、发布订阅模式(Publish-Subscribe Pattern)、反应堆模式(Reactor Pattern)、委托模式(Delegation Pattern)、过滤器模式(Filter Pattern)、
6.1 工厂模式¶
工厂模式(Factory Pattern)是一种用来创建对象的设计模式,属于类的创建型模式。在工厂模式中,我们在创建对象时不会对客户端暴露创建过程,并且可以通过一个共同的接口来指向新创建的对象。工厂模式基于不同的抽象程度,分三种写法。
6.1.1 简单工厂模式¶
import abc
class Payment(abc.ABC):
"""抽象支付类:规定每种支付方式都有同一个同样的对外调用接口方法"""
@abc.abstractmethod
def pay(self, money):
pass
class AliPay(Payment):
"""支付宝"""
def pay(self, money):
print("支付宝支付%d元" % money)
class WechatPay(Payment):
"""微信支付"""
def pay(self, money):
print("微信支付%d元" % money)
# 工厂角色
class PaymentFactory(object):
@classmethod
def create(cls, name):
if name == "ali":
return AliPay()
elif name == "wechat":
return WechatPay()
else:
raise TypeError("No such payment named %s." % name)
if __name__ == '__main__':
# 使用
factory = PaymentFactory()
payment = factory.create('ali')
payment.pay(100)
payment = factory.create('wechat')
payment.pay(100)
简单工厂模式在调用时,可以根据不同选择创建不同的对象,使用时不会对外暴露真正的创建对象过程,也提供了一个对外的统一接口,但是违背了solid的 "开闭原则",如果我们还需要新增一种支付手段,那就必须要对简单工厂SimpleFactory进行源码修改。
当然,如果明确固定了要创建的类,不会再新增的话则无所谓。开发中,我们以后开发的程序的数据肯定要保存到数据库的,一般数据库的数量是固定的,无非MySQl,Redis,MongoDB,这时候,我们可以基于简单设计模式来构建统一创建数据库操作对象的工厂类。除此之外,还有通知客户的方式也可以,很多项目都是基于邮件,短信,微信等几种手段通知客户信息的,这时候也可以利用简单工厂模式。
6.1.2 工厂方法模式¶
像上面的根据客户端选择不同而创建不同的支付方式的需求,我们如果希望在扩展新的支付方式类时,不要修改原有的代码的话,我们可以在简单工厂模式的基础上把SimpleFactory 抽象成不同的工厂,每个工厂对应生成自己的产品,这就是工厂方法模式。
工厂方法模式也叫虚拟构造器模式或多态工厂模式,在工厂方法模式中,父类负责定义创建对象的公共接口,而子类则负责生成具体的对象,这样做的目的是将类的实例化操作延迟到子类中完成,即由子类来决定究竟应该实体化哪一个类。
import abc
# 抽象支付类:规定每种支付方式都有同一个同样的对外调用接口方法
class Payment(abc.ABC):
@abc.abstractmethod
def pay(self, money):
pass
class AliPay(Payment):
def pay(self, money):
print("支付宝支付%d元" % money)
class WechatPay(Payment):
def pay(self, money):
print("微信支付%d元" % money)
class PaymentFactory(abc.ABC):
"""抽象工厂: 每种支付方式都有自己的工厂"""
@abc.abstractmethod
def create(self):
pass
class AliPayFactory(PaymentFactory):
"""支付宝工厂"""
def create(self):
return AliPay()
class WechatPayFactory(PaymentFactory):
"""微信支付工厂"""
def create(self):
return WechatPay()
if __name__ == '__main__':
factroy = AliPayFactory()
payment = factroy.create()
payment.pay(100)
factroy = WechatPayFactory()
payment = factroy.create()
payment.pay(500)
使用了工厂方法模式后,每个工厂就只负责生产自己的产品,避免了在新增产品时需要修改工厂的代码,遵循了"开闭原则",如果需要新增支付方式时,只需要增加相应的支付方式工厂类即可。
6.1.3 抽象工厂模式¶
工厂方法解决了"开闭原则"的问题,但是开发中支付的过程不能只是支付而已,肯定还会要处理之后的流程,比如支付结果的接收和处理。此时,如果每一个步骤我们就要写一个对应的工厂类,那我们就会需要创建很多很多类了。所以为了解决这个问题,我们就要需要抽象工厂类可以一次性生产多个产品或可以完成多个动作步骤,这就是抽象工厂。
import abc
class Payment(abc.ABC):
"""抽象支付类:规定每种支付方式都有同一个同样的对外调用接口方法"""
@abc.abstractmethod
def pay(self, money):
pass
class AliPay(Payment):
"""支付宝"""
def pay(self, money):
print("支付宝支付%d元" % money)
class WechatApy(Payment):
"""微信支付"""
def pay(self, money):
print("微信支付%d元" % money)
class AliPayResult(object):
"""支付宝支付结果处理"""
def handle(self):
print("支付宝转账成功!")
class WechatPayResult(object):
"""微信支付结果处理"""
def handle(self):
print("微信转账成功!")
class AbstractFactory(abc.ABC):
"""抽象工厂: 每种支付方式都有自己的工厂"""
@abc.abstractmethod
def create(self):
pass
@abc.abstractmethod
def get_result(self):
pass
class AliPayFactory(AbstractFactory):
"""支付宝工厂"""
def create(self):
return AliPay()
def get_result(self):
return AliPayResult()
class WechatPayFactory(AbstractFactory):
"""微信支付工厂"""
def create(self):
return WechatApy()
def get_result(self):
return WechatPayResult()
if __name__ == '__main__':
# 实例化工厂对象
factory = AliPayFactory()
# 创建支付对象
payment = factory.create()
payment.pay(100)
# 获取支付结果
result = factory.get_result()
result.handle()
# 实例化工厂对象
factory = WechatPayFactory()
# 创建支付对象
payment = factory.create()
payment.pay(200)
# 获取支付结果
result = factory.get_result()
result.handle()
抽象工厂模式与工厂方法模式的区别仅仅在于,抽象工厂中的一个工厂对象可以负责多个不同产品对象的创建。
6.2 外观模式¶
外观模式(Facade Pattern),也叫门面模式。门面模式来自于生活,门面通常是指建筑物的表面,尤其是最有吸引力的那一面。当人们从建筑物外面经过时,会因为欣赏其光鲜亮丽的表面,而忽略或无需去了解建筑内部构造的复杂性,这就是门面模式的使用方式。门面模式在程序开发中可以隐藏内部类的复杂实现代码的同时,为调用者提供了一个外观接口,以便调用者可以非常轻松的访问系统。
案例1:一个商城系统,在客户端下单时,会去判断下单的商品是否库存足够,会生成一个订单记录,同时把订单记录与商品进行绑定,计算本次用户需要支付的总费用,甚至会因为用户选择了优惠券而判断优惠券是否过期,统计使用了优惠券以后的真实价格等等一系列的操作,而在开发中,往往商品、订单、支付、优惠券等就是一个个独立的类/对象,此时客户端下单,我们直接把所有类/对象的调用代码暴露在外,那么将来如果商城系统需要功能调整时,如去除优惠券,或者增加积分,那么势必会影响到很多处客户端下单时所涉及的代码内容。 案例2:一个运维监控系统,在服务器宕机时需要发出警报通知管理员,而警报发出的过程中,也会需要调用很多类/对象去完成宕机原因的分析、宕机时的环境信息、还有多种不同的通知方式告知运维人员,假设直接调用这些类,那么将来警报功能调整时,也会影响大量的代码内容。
import abc
class AbstractAlarm(abc.ABC):
@abc.abstractmethod
def get(self, message):
"""接受并整理警报信息"""
pass
@abc.abstractmethod
def send(self, user):
"""发送警报内容给管理员"""
pass
class MailAlarm(AbstractAlarm):
"""邮件发送警报类"""
def get(self, message):
print(f"接受并整理警报信息{message}成邮件格式")
def send(self, user):
print(f"通过邮件发送警报内容给管理员{user}")
class SMSAlarm(AbstractAlarm):
"""邮件发送警报类"""
def get(self, message):
print(f"接受并整理警报信息{message}成短信格式")
def send(self, user):
print(f"通过短信发送警报内容给管理员{user}")
class VoiceAlarm(AbstractAlarm):
"""语音发送警报类"""
def get(self, message):
print(f"接受并整理警报信息{message}成语音内容")
def send(self, user):
print(f"通过语言电话发送警报内容给管理员{user}")
class Log(object):
def write(self, message):
"""记录警报信息到日志中"""
class AlarmFacade(object):
# 定义一个外观类,其中封装对子系统的复杂操作
def __init__(self):
self.logger = Log()
self.voice_alarm = VoiceAlarm()
self.sms_alarm = SMSAlarm()
self.mail_alarm = MailAlarm()
def alarm(self, user, message, level):
if level == 1:
self.mail_alarm.get(message)
self.mail_alarm.send(user)
elif level == 2:
self.sms_alarm.get(message)
self.sms_alarm.send(user)
elif level == 3:
self.voice_alarm.get(message)
self.voice_alarm.send(user)
self.logger.write(message)
if __name__ == '__main__':
facade = AlarmFacade()
facade.alarm("小明", "IP: 192.168.3.101,服务器宕机", 3)
6.3 链式模式¶
链式模式(Chain Pattern),也叫链模式、链式方法模式、链式调用或流式操作,是一种对象的行为型模式,主要的作用是简写对同一个对象的方法多次调用过程。
class Person(object):
def __init__(self):
self.range = 0
def walk(self, step):
print(f"走{step}步")
self.range += step
return self
def run(self, step):
print(f"跑{step}步")
self.range += step
return self
def get_range(self):
return self.range
p1 = Person()
ret = p1.run(5).walk(5).walk(5).run(5).get_range()
print(ret)
6.4 策略模式¶
策略模式属于一种对象的行为型模式,指对象有某个行为,但是在不同的场景中,该行为有不同的实现算法。
from abc import ABC, abstractmethod
class Item(object):
"""商品"""
def __init__(self, product, quantity, unit_price):
self.product = product
self.quantity = quantity
self.unit_price = unit_price
def total(self):
return round(self.unit_price * self.quantity,2)
class Order(object):
"""订单"""
def __init__(self, customer, cart, promotion=None):
self.customer = customer
self.cart = list(cart)
self.promotion = promotion
self.__total = 0
def total(self):
"""商品总金额"""
self.__total = sum(item.total() for item in self.cart)
return self.__total
def due(self):
"""应支付金额"""
if self.promotion is None:
discount = 0
else:
discount = self.promotion.discount(self)
return self.total() - discount
def __repr__(self):
return f"<Order total: {self.total():.2f} due: {self.due():.2f}>"
class Promotion(ABC):
@abstractmethod
def discount(self, order):
"""返回折扣价格"""
pass
class FidelityPromo(Promotion): # 折扣策略
"""拥有1000个或更多积分的客户可享受5%的折扣"""
def discount(self, order):
return order.total() * .05 if order.customer[1] >= 1000 else 0
class BulkItemPromo(Promotion): # 折扣策略
"""每件商品20件或以上可享受10%的折扣"""
def discount(self, order):
discount = 0
for item in order.cart:
if item.quantity >= 20:
discount += item.total() * .1
return discount
class LargeOrderPromo(Promotion): # 折扣策略
"""订购10件或10件以上不同商品可享受7%的折扣"""
def discount(self, order):
distinct_items = {item.product for item in order.cart}
if len(distinct_items) >= 10:
return order.total() * .07
return 0
xm = ("小明", 3500)
item1 = Item("鞋子", 200, 2)
item2 = Item("裙子", 600, 1)
item3 = Item("袜子", 30, 5)
item7 = Item("帽子", 50, 1)
item4 = Item("方便面", 50, 20)
item5 = Item("营养快线", 5, 10)
item6 = Item("充电宝", 59, 1)
item8 = Item("洗发水", 49, 2)
item9 = Item("沐浴露", 39, 1)
item10 = Item("肥皂", 9, 2)
cart = [item1, item2, item3, item4, item5, item6, item7, item8, item9, item10]
order = Order(xm, cart, FidelityPromo())
print(order)
# <Order total: 2464.00 due: 2340.80>
order = Order(xm, cart, BulkItemPromo())
print(order)
# <Order total: 2464.00 due: 2224.40>
order = Order(xm, cart, LargeOrderPromo())
print(order)
# <Order total: 2464.00 due: 2291.52>
6.5 装饰器模式¶
装饰器模式就是在现有的函数、类外层,套上一段逻辑代码,对其功能进行扩展和延伸,而且不会影响现有函数、类的本身结构。属于对象的结构型模式,常用于日志、性能测试、事务处理、数据缓存、权限校验、状态判断等开发场景。
# 装饰器
import time
# 装饰器,记录函数运行时间
def decorator(fun):
def wrapper():
start = time.time()
fun()
end = time.time()
print(f"fun run time is {start - end}")
return wrapper # 必须要返回内函数
# fn函数
def fn():
time.sleep(2)
print("fn is running")
# 装饰fn函数,让fn函数拥有计算耗时的功能,实际上操作的是内函数wrapper
test = decorator(fn)
test()
7. 装饰器¶
上面学习的装饰器模式在Python中,有默认的语法支持,那就是装饰器。装饰器的本质就是闭包函数,既是高阶函数也是嵌套函数。使用装饰器,可以简化上面的代码操作。
# 装饰器
import time
# 装饰器,记录函数运行时间
def decorator(fun):
def wrapper():
start = time.time()
fun()
end = time.time()
print(f"fun run time is {end - start}")
return wrapper # 必须要返回内函数
@decorator # 新增戴帽语法,表示装饰fn函数,等价于fn=decorator(fn)
def fn():
time.sleep(2)
print("fn is running")
fn()
Python内置的装饰器语法,本身比我们上面所编写使用的装饰器功能要更加强大,而且易于使用。
7.1 装饰器嵌套¶
# 装饰器
import time
# 装饰器
def decorator1(fun):
def wrapper():
print("decorator1-1")
fun()
print("decorator1-2")
return wrapper
def decorator2(fun):
def wrapper():
print("decorator2-1")
fun()
print("decorator2-2")
return wrapper
def decorator3(fun):
def wrapper():
print("decorator3-1")
fun()
print("decorator3-2")
return wrapper
@decorator3
@decorator2
@decorator1
def fn():
print("执行fn函数")
fn()
嵌套情况下,装饰器的执行顺序是从上往下开始,从下往上结束。
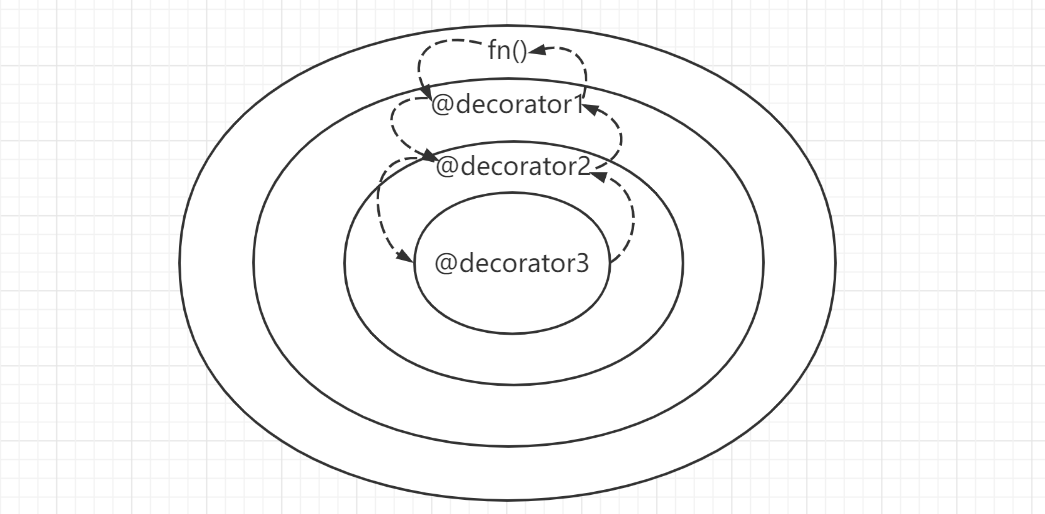
装饰器的写法无非函数装饰器与类装饰器两种,而被装饰的对象,也无非是函数、类、类方法三种,其实都是大同小异。
7.2 函数装饰器¶
前面的例子中使用的所有装饰器中,被装饰者都是无参数函数,而函数装饰器也支持装饰有参数的函数或有返回值的函数。
def decorator(func):
def wrapper(a, b):
if type(a) is not int or type(b) is not int:
print("a或者b不是整数!")
return 0
ret = func(a, b)
print(f"{a}+{b}={ret}")
return ret
return wrapper
@decorator
def fn(a, b):
return a + b
ret = fn(10, 2.0)
print(f"ret={ret}")
7.2.1 被装饰者是类¶
def singleton(cls):
# 外函数中声明一个变量,用于保存类的实例,那么这个实例对象将始终是通一个实例对象
__instance = None
def wrapper(*args,**kwargs):
# 使用nonlocal关键字将作用域扩展到上一级,拿到上一级的instance变量
nonlocal __instance
# 如果instance非空,那么将instance通过cls类(也就是Log)进行初始化
if __instance is None:
__instance = cls(*args, **kwargs)
return __instance
return wrapper
# 使用装饰器装饰一个类
@singleton
class Log(object):
def __init__(self, level="DEBUG"):
self.level = level
# 实例化装饰后的类
logger1 = Log()
print(id(logger1)) # 2142541852384
logger2 = Log()
print(id(logger2)) # 2142541852384
7.2.2 被装饰者是方法¶
def decorator1(fun):
def wrapper(self, *args, **kwargs):
print("decorator1-1")
ret = fun(self, *args, **kwargs)
print("decorator1-2")
return ret
return wrapper
class Person(object):
def __init__(self, name):
self.name = name
@decorator1
def speak(self, message):
ret = f"{self.name}: {message}"
print(ret)
return ret
p = Person("小明")
p.speak("你好!!!")
7.3 类装饰器¶
基于类实现的装饰器,是通过__call__或者类内部的方法来实现的,本质上还是函数装饰器。
class Decorator(object):
def __call__(self, func):
def wrapper():
print("decr1-1")
func()
print("decr1-2")
return wrapper
def decr2(self, func):
def wrapper():
print("decr2-1")
func()
print("decr2-2")
return wrapper
@classmethod
def decr3(cls, func):
def wrapper():
print("decr3-1")
func()
print("decr3-2")
return wrapper
@staticmethod
def decr4(func):
def wrapper():
print("decr4-1")
func()
print("decr4-2")
return wrapper
# 类作为装饰器,基于__call__方法
@Decorator()
def fn1():
print("fn1函数执行!")
fn1()
# 实例方法作为装饰器
@Decorator().decr2
def fn2():
print("fn2函数执行!")
fn2()
# 类方法作为装饰器
@Decorator.decr3
# @Decorator().decr3
def fn3():
print("fn3函数执行!")
fn3()
# 静态方法作为装饰器
@Decorator.decr4
# @Decorator().decr4
def fn4():
print("fn4函数执行!")
fn4()
8. 垃圾回收机制¶
Python 作为一门解释型语言,以代码简洁易懂著称。我们可以直接对名称赋值,而不必声明类型。名称类型的确定、内存空间的分配与释放都是由 Python 解释器自行内部处理的。Python 这种自动管理内存功能,极大的减小了程序员的负担,开发者完全可以不必关心其内部运作。但是内存的容量总归是有限的,Python解释器在内部申请内存和回收变量占用内存空间时,这些变量会怎么被回收呢?通过学习 Python 内部的垃圾回收机制,并了解其原理,我们就可以编写出更好的Python代码了。
8.1 基本概念¶
内存回收机制(garbage collection,简称:GC),也叫垃圾回收机制,是python解释器会定期清理掉内存中的垃圾数据的核心机制。因为主要由gc模块实现,因此有时候也叫GC回收机制。gc模块采用了引用计数法(reference counting)为主,标记-清除(Mark and Sweep)和分代回收(Generational garbage collector)两种机制为辅的策略实现了垃圾回收机制。其中,引用计数法用于跟踪和回收垃圾,在引用计数法的基础上,通过标记-清除机制解决容器对象可能产生的循环引用的问题,最后通过分代回收机制以空间换取时间的方式提高垃圾回收的效率。
8.2 引用计数¶
引用计数就是变量值被变量名关联的次数。
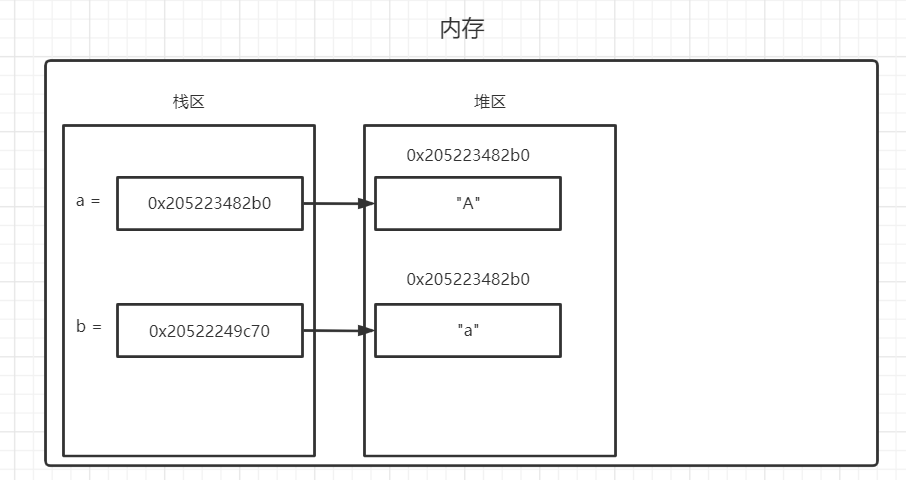
当一个数据可以被赋值给多个变量名或作为成员被容器类型的数据所使用,这个过程中,Python解释器会在内存中自动给这个数据绑定一个数字,叫引用计数。当数据的引用计数为0时,意味着该数据没有在程序中任何地方所使用,那么该数据就会被Python解释器自动清理的垃圾数据,如果垃圾数据没有被删除,则会一直保存在内存中,所以Python解释器删除这些垃圾数据的目的是要回收这些数据所占用的内存,并对这些内存空间再分配利用,达到节省内容的效果。
text = "hello world"
text = "hello moluo" # 因为text变量被指向到了新的字符串,所以旧字符串"hello world"因为没有被其他变量所绑定,所以属于垃圾数据。
我们可以通过sys模块提供的getrefcount()函数来获取当前数据对应的引用计数。
引用计数法的原理是每个对象维护一个ob_refcnt引用计数器(整型),用来记录当前对象被引用的次数,也就是来追踪到底有多少引用指向了这个对象。
当发生以下4种情况的时候,对象的引用计数器ob_refcnt+1:
| 条件 | 举例 |
|---|---|
| 对象被创建 | a=100 |
| 对象被引用 | b=a |
| 对象被作为参数,传到函数中 | func(a) |
| 对象作为一个成员,保存在容器类型的数据中 | data={a, "a", "b", 2} |
当发生以下四种情况时,该对象的引用计数器ob_refcnt-1,当指向该对象的内存的引用计数器为0的时候,该内存将会被Python解析器销毁:
| 条件 | 举例 |
|---|---|
| 当该对象的别名被显式销毁时 | del a |
| 当该对象的别名被赋予新的对象 | a=26 |
| 当该对象离开它的作用域,如func函数执行完毕,函数中的局部变量的引用计数-1,但是全局变量与闭包不会。 | |
| 当该对象从容器中删除时,或容器本身被销毁时。 | del data |
下图中,"A"的引用次数obrefcnt-1,而"a"的引用次数obrefcnt+1。
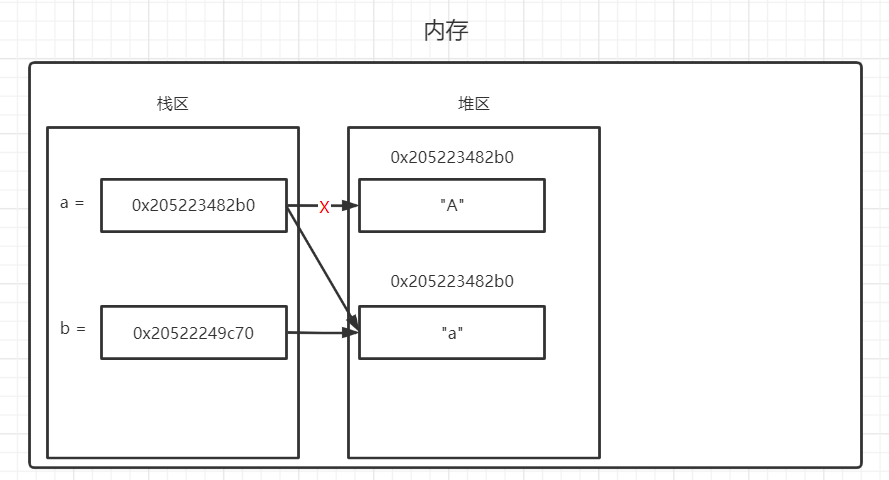
与前面查看数据的引用计数一样,也可以通过sys.getrefcount(变量)来查看对象的引用次数。
import sys
class Person(object):
pass
p = Person()
print(sys.getrefcount(Person()))
# 1,Person()本身代表1个对象,但是该对象并没有进行赋值,所以此处的1是因为把对象作为参数传入sys.getrefcount而增加的
print(sys.getrefcount(p))
# 2,p经过赋值引用了Person的实例对象,然后把p作为参数传递给sys.getrefcount,所以此处引用了2次。
# 因为小数据池和Python内存驻留机制的原因,所以针对数字、字符串、空元祖等小数据在系统属于常驻内存,为公用对象,
# 所以他们的引用次数,鬼知道是多少。。。。
print(sys.getrefcount('10202-222')) # 3
print(sys.getrefcount(1)) # 168
引用计数机制的优缺点:
| 优点 | 缺点 |
|---|---|
| 简单 | 维护引用计数消耗资源 引用次数的增加或减少,都会引发引用计数机制的执行 |
| 实时,一旦没有引用,内存就直接释放了。处理回收内存的时间分散, 而其他两种机制需要等待特定时机,时间相对集中。 |
容易出现循环引用的情况 |
8.3 标记-清除¶
上面提到引用计数法的缺点-循环引用问题。所谓的循环引用如下:
list1与list2相互作为对方成员,就会造成循环引用,即便不存在其他对象对它们的引用,list1与list2的引用计数也仍然为1,所占用的内存永远无法被回收,引用计数法对此是无解的,因此必须要使用其它的垃圾回收机制对其进行补充。
import sys
import ctypes
list1 = ["list1"]
# list2 = ["list1", ]
# list1.append(list2)
# list2.append(list1)
# print(list1)
# print(list2)
address = id(list1)
# list2_id = id(list2)
# print(sys.getrefcount(list1))
# print(sys.getrefcount(list2))
del list1
# del list2
print(sys.getrefcount(ctypes.cast(address, ctypes.py_object).value))
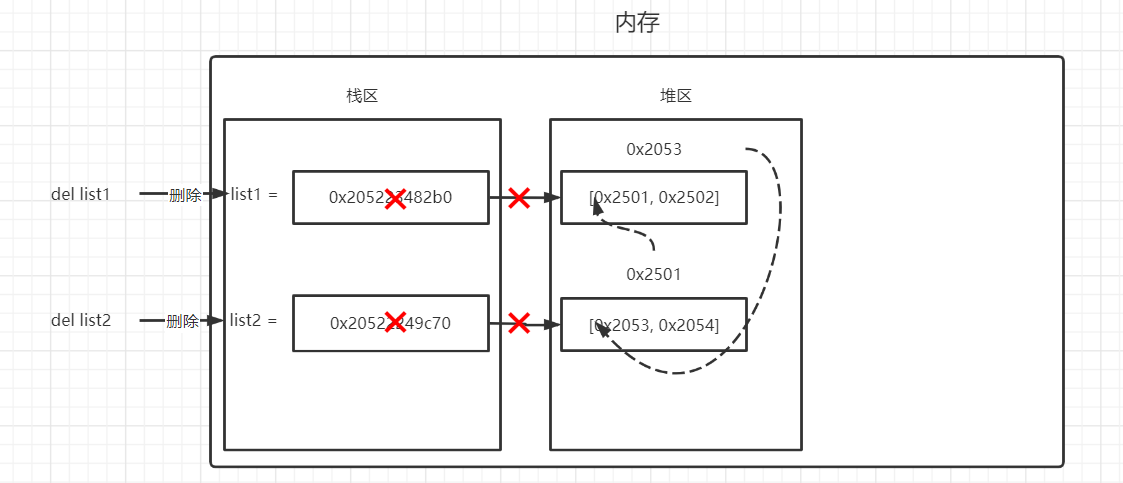
上面可以看到,list1和list2的变量即便删除了,还是驻留在内存中。除了列表,所有的容器对象(list,set,dict,class,instance)都可以包含对其他对象的引用,所以都可能产生循环引用问题。而标记-清除机制就是为了解决循环引用的问题而设计的,只针对容器类型。
标记-清除算法主要有两阶段构成,即第一阶段标记(Mark)与第二阶段清除(Sweep)。当应用程序可用的内存空间耗尽时,Python解释器就会停止整个应用程序,进行标记清除的这两段操作。
标记阶段(Mask):遍历程序内部的可能会造成循环引用容器对象,如果还有其他对象引用该容器对象,则把该容器对象标记为可达(reachable)。在Python解释器内部实际上遍历所有的栈区中GC Roots对象(也就是上面提到的所有保存在栈区中的变量名等内容),并把所有GC Roots对象直接或间接关联起来的对象标记为可达状态,没有关联的则不会标记。
清除阶段(Sweep):再次遍历程序内部的可能会造成循环引用容器对象,如果发现某个对象没有标记为可达,则就将其回收,从而解决容器类型数据带来的循环引用问题。
标记清除的优点在于可以解决循环引用的问题,并且在整个算法执行的过程中没有额外的开销。当然也有缺点:
- 当执行标记清除时正常的程序将会被阻塞。
- 标记清除算法在执行很多次数后,程序的堆空间会产生一些小的内存碎片。
8.4 分代回收¶
基于标记-清除这种回收机制,每次gc回收内存时,都需要把所有容器对象的引用计数都遍历一遍,这是非常消耗时间的,于是引入了分代回收来提高回收效率。
分代回收技术是上个世纪80年代初发展起来的一种垃圾回收机制,也是Java 垃圾回收的核心算法,其核心思想是在历经多次垃圾回收扫描以后,都没有被回收的对象,gc机制就会认为,该对象是常用数据(常驻数据),gc机制对其扫描的频率就会降低,在执行标记-清除机制时可以有效减小遍历的对象数量,从而提高垃圾回收的速度,是一种以空间换时间的方法策略。
所谓的分代指的是根据存活时间来把变量划分不同等级(也就是不同的代),在Python解释器内部通过NUMGENERATIONS变量来设置为3代,分为 0(新生代),1(青春代),2(老年代) 三代,所有的新建对象都是 0 代对象,当某一代对象经历过垃圾回收,依然存活,就被归入下一代对象(按新生代->青春代->老年代顺序),每个代都由一个 gcgeneration 数据结构来保存。Python的gc模块的分代回收机制策略如下:
- 每新增 701 个需要 GC 的对象,触发一次新生代 GC
- 每执行 11 次新生代 GC ,触发一次中生代 GC
- 每执行 11 次中生代 GC ,触发一次老生代 GC (老生代 GC 还受其他策略影响,频率更低)
"""获取的gc模块中自动执行垃圾回收的频率。"""
print(gc.get_threshold()) # (700, 10, 10)
# 当然,我们也可以临时设置gc模块自动执行垃圾回收机制的频率
# gc.set_threshold(threshold0[, threshold1[, threshold2]) 设置自动执行垃圾回收的频率。
例如,假设阀值默认不变的情况下,(700,10,10),我们可以通过gc.get_count来查看gc机制自动执行垃圾回收的计数器。