函数基础¶
设计一个程序输出一下图案效果:
根据已经学过的内容,我们的实现方式如下:
for row in range(3):
for col in range(row*2+1):
print("*", end="")
print()
for row in range(5):
for col in range(row*2+1):
print("*", end="")
print()
相信大家一定看出来了,上面的程序虽然实现了要求的功能,但是出现了大量重复代码,对于阅读和维护整个程序都会变得十分麻烦。
所以我们需要解决掉这个问题,因此,我们需要学习函数!
如果在开发程序时,需要多次使用同一段代码,为了提高代码的编写效率以及方便以后重复使用,可以把具有特定独立功能的代码块使用def关键字组织成一个具有名称的整体代码块,这就是函数(function)。简单说,函数就是一段封装好的,可以重复使用的代码块,它可以使程序变得更加模块化(让代码关联起来形成一个整体),避免大量重复的代码。
刚才的程序使用函数进行改进,代码如下:
def xingxing(line):
for row in range(line):
for col in range(row*2+1):
print("*", end="")
print()
xingxing(line=3)
xingxing(line=5)
扩展:
编程中的函数与数学中的函数虽然都是描述输入与输出之间关系的工具,但是使用上有很多的区别。例如,y = f(x) :
在数学中,研究的是自变量x与因变量y之间的逻辑映射关系,重点在x与y,不涉及到f的实现。
在编程中,研究的是如何编写代码实现函数f,通过x去得到y,重点在f。
我们可以使用编程代码编写函数来解决数学问题。
1. 基本语法¶
1.1 函数的声明与使用¶
所谓的声明函数,也就是创建一个函数,可以理解为通过关键字def使用函数名代表将一段可以重复使用的代码块。
具体的语法格式如下:
def 函数名(参数: 参数的类型, 参数: 参数的类型, ...) -> 返回值的类型:
'''
# 函数说明文档,告诉别人这个函数的作用以及如何使用该函数的说明文字
params: 参数
return: 结果
'''
# 中间是 实现特定功能的代码块
return 返回值
定义了函数之后,就相当于在内存中有一个变量,该变量代表了一个具有某些功能的代码块。函数在声明以后并不会执行函数中的代码块,想要执行这些代码块,需要调用该函数才行,同一个函数可以被重复调用多次。
函数调用语法:
每次调用函数时,函数中的代码都会从头开始执行,当这个函数中的代码执行到最后或者遇到关键字return时,意味着调用结束了。
import time
def print_word(content: str) -> None:
"""
逐字打印效果
:param content: 打印的内容
:return:
"""
for letter in content:
print(letter, end="")
time.sleep(0.05)
print()
print_word(content="在Python中使用 def 关键字来定义函数。")
# print_word(content="在Java中使用 function 关键字来定义函数。")
help(print_word)
debug模式运行:
# 一个Python程序文件中,可以定义很多个不同的函数,每一个函数都可以反复多次。
# 函数的声明
def bar():
print("bar1")
print("bar2")
print("bar3")
# 函数的声明
def foo():
print("foo1")
print("foo2")
print("foo3")
# 函数调用,一个函数可以调用多次,每次都是从第一行开始执行
foo()
# 函数调用
bar()
# 函数调用
foo()
1.2 文档说明¶
在工作中,我们经常会需要根据各种不同的情况对代码进行封装成各种不同功能的函数,有时候函数多了,或者函数的代码多了,这时候,会让人一下子记不起来或者看不明白这个函数有什么作用,所以我们可以使用函数的文档说明,来提示使用者,当前函数的用法或者效果。
def triangle():
"""打印一个5行的三角形图案"""
line: int = 5
for i in range(line):
print(" " * (line - i), end="")
print("*" * (i * 2 + 1))
# 通过help可以看到函数的文档信息
help(triangle)
# Help on function triangle in module __main__:
#
# triangle()
# 打印一个5行的三角形图案
print(triangle.__doc__)
# 打印一个5行的三角形图案
针对函数的使用,如果我们使用的编辑器是ide工具,一般都会对函数本身使用说明文档,进行提示:
- 我们可以通过鼠标悬放在函数名上方就可以看到函数的说明文档了。
- 我们还可以通过Ctrl+鼠标左键,就可以直接跳转到函数声明位置(有可能是当前文件,也可能是python内置的python文件位置)。
- 当我们如果跳转到了其他文件,希望能快速返回之前的鼠标点击位置,可以使用alt+方向键(← 和 →)
如果同一个文件下,继续使用Ctrl+鼠标左键
如果我们使用的不是IDE工具,但是又想要了解函数的声明文档,可以使用以下2种方式:
1.3 函数参数¶
声明一个计算1-100的和的函数。
def calc_number():
"""计算start~end之间的整数的累加和"""
start: int = 1
end: int = 100
result: int = 0
for i in range(start, end+1):
result += i
print(result)
calc_number()
calc_number()
calc_number()
像上面我们举的例子,如果我想计算1+2+...+50的累加和,或者1+2+...+10的累加和怎么弄?再声明一个新的函数吗?
我们会发现计算1-100和与计算1-200的和的步骤是相同的,只有需要改变range()的第二个选项参数。
def calc_number(end: int):
"""
计算start~end之间的整数的累加和
:param end: 结束数字
"""
start: int = 1
# end: int = 100
result: int = 0
for i in range(start, end+1):
result += i
print(result)
calc_number(100) # 1+2+...+100=? end=100
calc_number(50) # 1+2+...+50=? end=50
calc_number(10) # 1+2+...+10=? end=10
为什么要使用参数?把end变量放到函数外面不可以吗?
def calc_number():
"""
计算start~end之间的整数的累加和
"""
start: int = 1
# end: int = 100
result: int = 0
for i in range(start, end+1):
result += i
print(result)
end: int =100
calc_number() # 1+2+...+100=? end=100
end: int =50
calc_number() # 1+2+...+50=? end=50
end: int =10
calc_number() # 1+2+...+10=? end=10
把end放在函数外面以后,的确实现了类似的效果,但是如果每次调用函数都要对end进行一次赋值的话,当将来需要计算20~50之间的累加和时,很明显,就会出现一种尴尬情况,就是每次调用函数时都要对2个变量进行赋值,很麻烦。而且这样的代码,没办法让人清晰的知道end和calc_number函数是有关联的。所以,使用参数无疑是最好的选择。有了函数的参数以后,还有一些使用上的注意事项,代码:
"""函数的参数: 如果希望函数中的某些变量在每一次函数调用都发生变化,那么可以把这个变量作为函数参数即可"""
"""
1. 在函数声明时,如果声明了参数,那么在调用时,必须填写足够数量的数据才行。
2. 函数会随着参数的越来越多而变得越来越强大,函数也会变得越来越复杂,会带来使用函数的难度提升,
因此建议声明的函数的时候,不要声明太多的参数,0~6个左右。
"""
def calc_number(start: int, end: int):
"""
计算start~end之间的整数的累加和
:param end: 结束数字
:param start: 开始数字
"""
# start: int = 1
# end: int = 10
result: int = 0
for i in range(start, end+1):
result += i
print(result)
calc_number(1, 100) # 1+2+...+100=? start=1, end=100
num: int = 20
calc_number(num, 50) # 1+2+...+50=? start=20, end=50,虽然写的是num,但是实际上传递进去函数中给start的是num的值
calc_number(5, 10) # 1+2+...+10=? start=5, end=10
"""函数中的参数或者函数内部声明的变量,都是无法提供给函数外部去使用的。"""
# print(start) # NameError: name 'start' is not defined
# print(result) # NameError: name 'start' is not defined
1.3.1 形参和实参¶
函数的参数可以解决上面的问题,函数的函数可以使函数的功能更加强大,让函数变得更加灵活:
# 案例1
def cal_sum(temp: int): # temp就是引入的函数形式参数
ret: int = 0
for i in range(1,temp+1):
ret+=i
print(ret)
cal_sum(100) # 每次调用可以根据需要传入需要的值,这个具体的值成为实际参数简称实参。
cal_sum(101)
# 案例2
def add():
x: int = 10
y: int = 20
print(x+y)
def add(x: int, y: int): # 声明的参数称之为形式参数,简称形参
print(x + y)
# 调用add函数 # 将调用过程中传入的值称之为实际参数,简称实参
add(5, 6) # 将5赋值给x,将6赋值给了y ,函数体将x+y,即5+6计算出来,打印
# 调用add函数
add(10, 5) # 将10赋值给x,将6赋值给了5 ,函数体将x+y,即10+5计算出来,打印
在函数的定义阶段 括号内写的变量名,叫做该函数的形式参数,简称形参。
在函数的调用阶段,括号内实际传入的值,叫做实际参数,简称实参。
上面例1中,temp就是的函数的形参,而每次调用根据需要传入的值,比如100,101都是实参。
形参就相当于变量名,而实参就相当于变量的值,函数调用传参的过程 就是给形参变量名赋值的过程。
一般情况下,函数参数只有在函数调用阶段有效,函数运行结束,参数作为垃圾被内存释放(也就是删除)。
函数在调用过程中,如果出现函数名一样的情况,那么调用的代码只会执行最近声明的一个函数,同时,函数内部的代码执行完成以后,会直接跳转到调用函数的代码位置接着往下继续执行。
函数代码的执行分析过程:
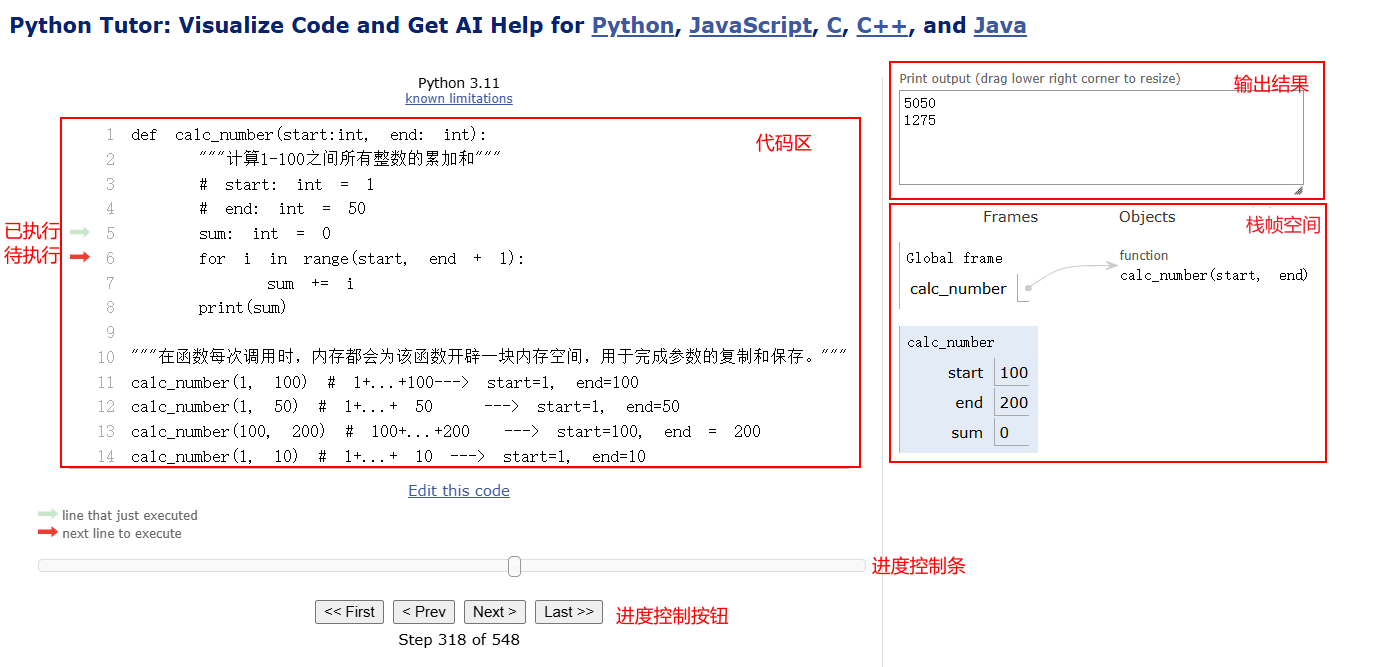
代码执行过程:https://pythontutor.com/live.html#mode=edit
函数在调用时,python解释器会开辟一个临时的内存空间(栈帧空间),用于保存函数调用时产生的参数、参数值、变量、变量值、函数调用地址、函数的结束。这个栈帧空间会在函数调用结束以后被自动删除,当下一次函数被调用时,又会出现一个新的栈帧空间,但是这个空间不再是之前的栈帧空间。
1.3.2 位置参数¶
位置参数(positional argument),指在函数调用时,按照形参的顺序逐个传递到函数中进行赋值的实参。
# 例1
def add(x: int,y: int): # x,y是形参,用来接收实参
print(x+y)
add(2,3) # 2,3 就是位置参数,分别传递给形参x, y,相当于在函数内部会执行如下操作:x=2,y=3
# 例2
def add(x: int,y: int,z: int):
print(x+y)
add(2,3) # 缺少一个实际参数传递给z
# 例3
def add(x: int,y: int):
print(x+y)
add(2,3,4) # 缺少一个形式参数接收给z
1.3.3 关键字参数¶
关键字参数(keyword argument)可以避免牢记参数位置的麻烦,可以使函数的调用和参数传递更加灵活方便。关键字参数是指使用键值对的方式来确定输入函数中的实参。通过此方式指定函数实参时,不再需要与形参的位置完全一致,只要将参数名写正确即可。
def print_stu_info(name: str,age: int,height: float,weight: float, job: str):
print("姓名:",name)
print("年龄:",age)
print("身高:",height)
print("体重:",weight)
print("职务:",job)
print_stu_info("张三", 23, 1.77, 70,"班长")
print_stu_info(name="张三", height=1.80, weight=86, job="学委", age=23)
# 关键字参数必须写在位置参数之后。
print_stu_info("张三", height=175, weight=65, job="团委", age=23)
如果在函数调用时,同时使用位置参数和关键字参数进行混合传参。则需要注意,关键字参数必须位于所有的位置参数之后。为了增强函数的参数规范和让代码兼容性更强,在Python3.8版本以后还提供了两个参数限定符,用于划分位置参数与关键字参数的先后顺序,这在 API 设计和保持向后兼容性时非常有用。
1.3.3.1 参数限定符¶
1.3.3.1.1 /¶
/ 在 Python 函数声明中用于指示仅限位置参数,确保这些参数只能通过位置传递,而不能通过关键字传递。
代码:
def foo(a: ..., b: ..., /, c: ..., d: ...):
print(f"a: {a}, b: {b}, c: {c}, d: {d}")
"""正确的写法"""
foo(10, 20,c=3,d=4)
foo(10, 20,30,40)
"""错误写法"""
# foo(a=10, b=20,c=30,d=40)
# TypeError: foo() got some positional-only arguments passed as keyword arguments: 'a, b'
/之前的参数(如a和b)是仅限位置参数。/之后的参数(如c和d)可以是位置参数或关键字参数。
1.3.3.1.2 *¶
/ 在 Python 函数声明中用于指示仅限关键字参数,确保这些参数只能通过关键字方式传递,而不能通过位置传递。
代码:
def foo(a: ..., b: ..., /, c: ..., d: ..., *, e:..., f:...):
print(f"a: {a}, b: {b}, c: {c}, d: {d}, e: {e}, f: {f}")
"""正确写法"""
foo(10, 20,c=3,d=4, e=5, f=6)
foo(10, 20,30,40, e=50, f=60)
"""错误写法"""
# foo(10, 20,30,40, 50, 60)
# TypeError: foo() takes 4 positional arguments but 6 were given
# 类型错误:foo() 需要传递4个位置参数,但是传递了6个,多了。
*之前的参数(如c和d)可以是位置参数或关键字参数。*之后的参数(如e和f)仅限关键字参数。
1.3.4 默认参数¶
在定义函数时,直接给形参指定一个默认值,这种参数称之为默认参数,也叫可选参数。同理在定义函数时,没有默认值的参数,则为必填参数。
""""""
"""必填参数与可选参数[默认参数]"""
def print_stu_info(name: str, age: int, height: float, weight: float, gender: bool=True, job:str='无') -> None:
"""
打印学生信息
:param name: 姓名
:param age: 年龄
:param height: 身高
:param weight: 体重
:param gender: 性别,默认值为True,表示男生
:return:
"""
gender = '男生' if gender else '女生'
print(f"{name=}, {age=}, {height=}, {weight=}, {gender=}, {job=}")
print_stu_info('小红', 17, 1.68, 56, False)
print_stu_info('小明', 16, 1.77, 60)
print_stu_info('小江', 17, 1.74, 58, job='学委')
print_stu_info('小江', 17, 1.74, 58, True, '学委')
"""补充,不能对同一个参数使用多种传参方式:例如:下面的height,1.77按照编写的顺序会默认作为height参数的值,之后又使用height=60以关键字参数的方式进行指定传递就会报错"""
# print_stu_info('小明', 16, 1.77, height=60)
# TypeError: print_stu_info() got multiple values for argument 'height'
# 类型错误:调用print_stu_info函数,传递了多个值给参数 'height'
定义函数时,默认参数必须写在所有必填参数的后面,否则报错!
def print_stu_info(name: str,gender: str="male", age: int): # 程序出错,无法运行!age是必填参数,不能写在gender之后。
# SyntaxError: parameter without a default follows parameter with a default
print("学员姓名:",name)
print("学员年龄:",age)
print("学员性别:",gender)
print_stu_info("张三",23)
1.3.5 不定长参数¶
不定长参数也叫可变长参数、收集参数或剩余参数,在Python函数,我们可以在定义函数时使用*args和**kwargs接收不定长参数。*args用于以元组格式来接收位置参数;**kwargs用于以字典格式来接收关键字参数列表,你可以把不定长参数理解为参数的组包。
# *args
"""
可变长参数在声明函数时,必须写在位置参数之后,写在关键字参数之前,否则在调用函数时会报错!
"""
def my_max(a, b, *args, c, d):
"""
:param *args: 可边长参数,用于以元组格式接收所有的剩余位置参数
:return:
"""
print(f"{a=}, {b=}, {args=}, {c=}, {d=}") # a=1001, b=200, args=(30, 40, 11, 13), c=15, d=21
max_value = args[0]
for item in args[1:]:
if item >= max_value:
max_value = item
print(max_value)
my_max(1001, 200, 30, 40, 11, 13, c=15, d=21)
# 最后2个参数必须以关键字参数的方式传递到函数中,否则会报错:
# my_max(1001, 200, 30, 40, 11, 13, 15, 21)
# TypeError: my_max() missing 2 required keyword-only arguments: 'c' and 'd'
# **kwargs
def print_stu_info(a, b, **data):
"""
打印学生信息
:param **data: 可边长参数,以字典格式接受所有的剩余关键字参数
:return:
"""
print(f"{a=}, {b=}{data=}") # a=100, b=200data={'name': '小明', 'age': 17}
print_stu_info(name="小明", age=17, a=100, b=200)
print_stu_info(100, 200, name="小明", age=17)
print_stu_info("小明", 17) # 可以不传递数据给**data
"""错误用法"""
# **data只能接受关键字参数,你也可以不传递关键字,但是绝不能接受位置参数
# TypeError: print_stu_info() takes 2 positional arguments but 3 were given
# print_stu_info("小明", 17, 1.70)
同时混合使用*args和**kwargs:
"""*args 和 **kwargs 混合使用"""
def foo(*args, **kwargs):
print(f"{args=}, {kwargs=}")
"""正确写法"""
foo() # args=(), kwargs={}
foo(10,20)
foo(10, 20, a=10, b=20)
"""注意事项:*args的左边只能是位置参数,*args的后面只能是关键字参数"""
def foo(a, b, *args, c, d=100, **kwargs):
print(f"{a=}, {b=}, {args=}, {c=}, {d=}, {kwargs=}")
"""正确用法"""
foo(a=10, b=20, c=30, d=40) # a=10, b=20, args=(), c=30, d=40, kwargs={}
foo(10, 20, c=30, d=40) # a=10, b=20, args=(), c=30, d=40, kwargs={}
foo(10, 20, 30, 40, c=30, d=40) # a=10, b=20, args=(30, 40), c=30, d=40, kwargs={}
foo(10, 20, 30 ,40, c=30, d=40, f=50, e=60) # a=10, b=20, args=(30, 40), c=30, d=40, kwargs={'f': 50, 'e': 60}
注意点:
1、参数
arg、*args、**kwargs三个参数的位置必须是一定的。必须是(arg,*args,**kwargs)这个顺序,否则程序会报错。2、在调用函数时,可以不给不定长参数传递值。
3、
args和kwargs其实只是编程人员约定的变量名字,args是 arguments 的缩写,表示位置参数;kwargs是 keyword arguments 的缩写,表示关键字参数。
1.3.5.1 参数解包¶
* 用于解包可迭代对象(如列表、元组等),将其中的元素作为单独的位置参数传递给函数。
def func(a: int, b: int, c: int):
print(f"a: {a}, b: {b}, c: {c}")
arr: list = [1, 2, 3]
func(*arr) # 等价于 arr(1, 2, 3)
** 用于解包字典,将其中的键值对作为关键字参数传递给函数。
def func(a: int, b: int, c: int):
print(f"a: {a}, b: {b}, c: {c}")
data = {'a': 1, 'b': 2, 'c': 3}
func(**data) # 等价于func(a=1, b=2, c=3)
1.4 函数返回值¶
到目前为止,我们创建的函数都只是对传入的数据进行了处理,处理完了就结束。但实际上,在更多场景中,我们还需函数将处理的结果反馈回来。通过在函数内部使用关键字return语句可以返回函数的结果为函数的调用处,支持任意类型的数值。
1.4.1 基本格式¶
返回值代表的就是函数内部return后面的信息,函数的结果,可以没有,也可以有一个或者多个,但是return只能执行一次
1.4.2 默认返回值¶
在 Python 中,有一个特殊的常量 None(N 必须大写)。和 False 不同,它不表示 0,也不表示空字符串,而是表示没有值,即内存中什么都没有,一般称为空值。None 是 NoneType数据类型的唯一值(其他编程语言可能称这个值为 null、nil 或 undefined),也就是说,我们不能再创建其它 NoneType类型的变量,但是可以将 None 赋值给任何变量,表示该变量的值为空值,什么都没有。
在Python,函数中的代码块如果没有return语句或者return后没有任何变量或代码,则默认函数没有任何结果,即结果为None,例如:print()函数就没有返回结果(也叫没有返回值)。
1.4.3 返回多个值¶
return也可以返回多个值,python其实会将多个值放在一个元组中元组返回。
def login(user: str, pwd: str) -> tuple:
flag: bool = False
if user == 'moluo' and pwd == "123456":
flag = True
return flag, user
# ret = login("admin", "123456")
flag, user = login("admin", "123456")
if flag:
print("{}登陆成功!".format(user))
else:
print("用户名或者密码错误!")
2. 扩展概念¶
2.1 函数嵌套与闭包¶
# 可以在函数内部声明一些函数,这些函数,在函数的外界无法使用。
def foo():
def bar():
print("bar功能函数")
print("foo功能函数")
bar()
foo()
"""
foo功能函数
bar功能函数
"""
# bar() # name 'bar' is not defined,嵌套函数bar则无法在外界使用。
函数嵌套是闭包实现的基础,所谓闭包指代内函数的代码块中使用了来自外函数的变量,导致外函数的代码块被调用并执行结束以后,其变量因为被内函数捕获而无法被释放的特殊函数嵌套结构。
from typing import Callable
"""闭包(closure):指代在嵌套函数中,内函数中的代码块使用了来自外函数中定义的变量。这个操作就是闭包"""
def outer():
"""外函数"""
a: int = 0
def inner():
# 可以通过nonlocal关键字语句,调用来自外函数中的变量或者参数
nonlocal a
a += 1
return a
return inner
func: Callable = outer()
print(func()) # a=1
print(func()) # a=2
print(func()) # a=3
代码分析:https://pythontutor.com/render.html#mode=display
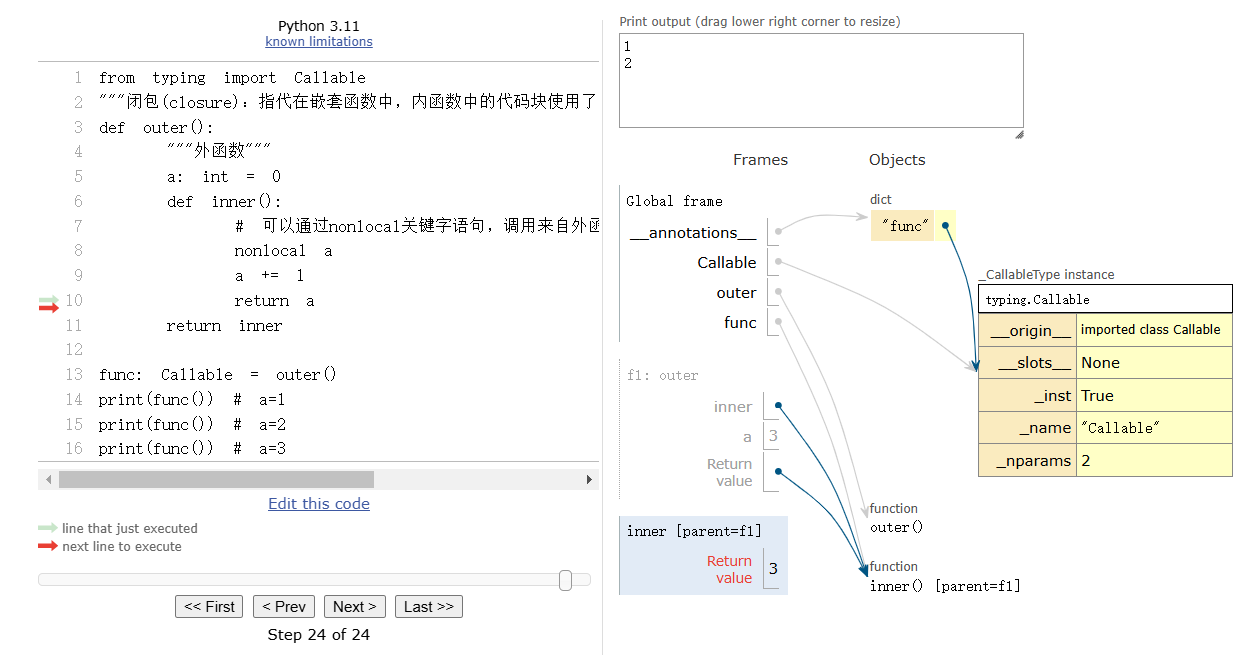
通过 __closure__ 属性可判断是否是闭包:
print(func.__closure__) # 输出包含 cell 对象的元组(非空则为闭包)
print(func.__closure__[0].cell_contents) # 输出 10(存储的外部变量值)
注意:函数嵌套≠闭包。以下函数嵌套中,因为内函数并没有引用到外函数的变量,所以并没有形成闭包。
2.2 作用域¶
在Python中,作用域(Scope) 是指一个变量可以被访问和引用的范围,决定了变量的生命周期(Lifetime,指变量、对象或资源从创建到销毁的整个过程)以及可见性(visibility,指代变量在哪些地方可以被使用)。
理解作用域对于编写清晰、可维护的代码来说至关重要,因为在代码运行过程中,并不是所有变量都会一直被保存到最后的,而是大多数变量都在程序运行过程中不断的建立和销毁,以此来避免程序运行过程中,因为内存被占用过多而导致出现异常。
要想理解Python的作用域,那么首先我们要知道在python中,有些变量可以在整段文件中任意位置使用,有些变量只能在函数内部使用,实际上这是因为变量创建时所在的代码块区域不同而被python解释器分配到不同命名空间里面所导致的。
2.2.1 命名空间¶
命名空间(Namespace)是python解释器实现把标记符名称(变量名、函数名、类名等)与数据对象进行映射的容器(字典),并非真实的内存空间。
命名空间是Python用来组织和管理标记符名称的核心机制,确保标记符名称在当前命名空间的唯一性。
2.2.1.1 命名空间的类型¶
Python中的命名空间的分类,主要有以下4种:
| 命名空间类型 | 成员信息 | 生命周期 | 访问方式 |
|---|---|---|---|
| 内置命名空间 Built-in Namespace |
Python内置的函数、异常和对象 如 print、len、int等 |
开始:在 Python 解释器启动时创建, 结束:在Python解释器退出时销毁。 在整个程序运行期间始终可用。 |
import builtinsprint(builtins.__dict__) |
| 全局命名空间 Global Namespace |
模块文件中顶格声明的变量、函数和类 | 开始:在模块加载时创建, 结束:模块代码执行结束或卸载时销毁。 每个模块都有自己的全局命名空间。 |
print(globals()) |
| 局部命名空间 Local Namespace |
函数、方法或类内部的变量和参数、函数 | 开始:在函数、方法或类调用时创建, 结束:函数、方法或类执行结束时销毁。 每次调用函数时都创建新的局部命名空间。 |
print(locals()) |
| 嵌套命名空间 Enclosing Namespace |
外函数的变量和参数、内函数 | 开始:在外函数调用时创建, 结束:处于引用状态下,会一直至程序结束。 每次调用外层函数时都创建新的局部命名空间。 |
print(locals()) |
注意:
命名空间的类型还有7种的说法:除了以上4种以外,还有模块命名空间,类命名空间,实例命名空间。
代码:
"""查看内置命名空间的标记符相关信息"""
import builtins
print(builtins.__dict__)
print(dir(builtins))
"""查看全局命名空间中的标记符相关信息"""
print(globals())
"""查看局部命名空间的标记符相关信息"""
def mydiv(x, y) -> float:
result: int = x / y
print(locals()) # 查看局部命名空间下的标记符信息
return result
print(mydiv(10,3))
"""查看嵌套命名空间的标记符相关信息"""
def outer(places: int):
def inner(x, y) -> float:
result: int = x / y
data: str = f"{result:.{places}f}"
return float(data)
print(locals()) # 查看嵌套命名空间下的标记符信息
return inner
mydiv = outer(3)
print(mydiv(10,3))
2.2.2 作用域的原理分析¶
因为不同的命名空间下可以存在相同的变量名,为了避免因为同变量名导致出现污染现象(即同名变量覆盖值),Python解释器在程序执行时采用了作用域规则(Scope,也叫作用域机制)来规定不同命名空间中的变量在程序执行时,哪些地方可以被访问,也就是前面所说的变量的有效使用范围。
为了更好对命名空间中的标记符名称实现分层管理和有效查找,Python解释器采用3个方案来配合实现作用域规则限定变量的可见性:
- 划分多个不同范围等级的作用域与每个命名空间对应,将变量限制在最小的必要范围内,减少了变量的污染,确保了程序的清晰性。
- 通过LEGB规则逐层查找变量所在的作用域,允许内层作用域中的代码通过指定方式访问到外层作用域下的变量,扩展了程序的灵活性和可扩展性。
- 当内部作用域的代码要修改外部作用域下的变量,Python解释器提供了global与nonlocal这两个关键字语句给开发者修改变量。
2.2.2.1 作用域分类¶
对应于每种不同的命名空间,作用域也分成了以下4类:
| 作用域 | 域内变量的作用范围 | 域内变量的生命周期 |
|---|---|---|
| 局部作用域 Local Scope |
定义:当前函数或类的内部声明的变量, 访问:只能在定义它的函数或类的内部被访问。 修改:只能在定义它的函数或类的内部中修改。 |
开始:从函数调用开始, 结束:到函数执行结束。 |
| 嵌套作用域 Enclosing Scope |
定义:外函数声明的变量, 访问:内函数没有定义同名变量,则可以直接访问(取值), 修改:内函数修改变量值,需使用nonlocal关键字语句引入。 |
开始:从外层函数调用开始, 结束:到外层函数执行结束。 |
| 全局作用域 Global Scope |
定义:当前模块文件顶格缩进声明的变量, 访问:在当前模块文件中都可以访问,其他模块中需要导包引入 修改:函数或类的内部修改变量值,需使用global关键字引入。 |
开始:从变量定义开始, 结束:到程序结束或变量所在的模块被销毁。 |
| 内建作用域 Built-in Scope |
定义:Python解释器内置的变量和函数(如 print, len 等)等,访问:在任何地方都可以访问。 修改:函数或类的内部修改变量值,需要用global关键字引入。 |
开始:从Python解释器启动时开始, 结束:到Python解释器退出运行。 |
代码:
"""例 1:局部作用域 (Local)"""
def foo():
x: int = 10 # 局部变量
print(f"{x=}")
foo()
# print(f"{x=}") # 报错,x 是局部变量,外部无法访问
"""例 2:嵌套作用域 (Enclosing)"""
def outer():
x: int = 20 # 嵌套作用域变量
def inner():
print(f"{x=}") # 可以直接访问外层函数的变量
inner()
outer()
"""例 3:全局作用域 (Global)"""
x = 30 # 全局变量
def bar():
print(f"{x=}") # 访问全局变量
bar()
print(f"{x=}") # 访问全局变量
# 例 4:内置作用域 (Built-in)
print("Hello, World!") # print 是内置函数
print(len([1, 2, 3])) # len 是内置函数
2.2.2.2 LEGB¶
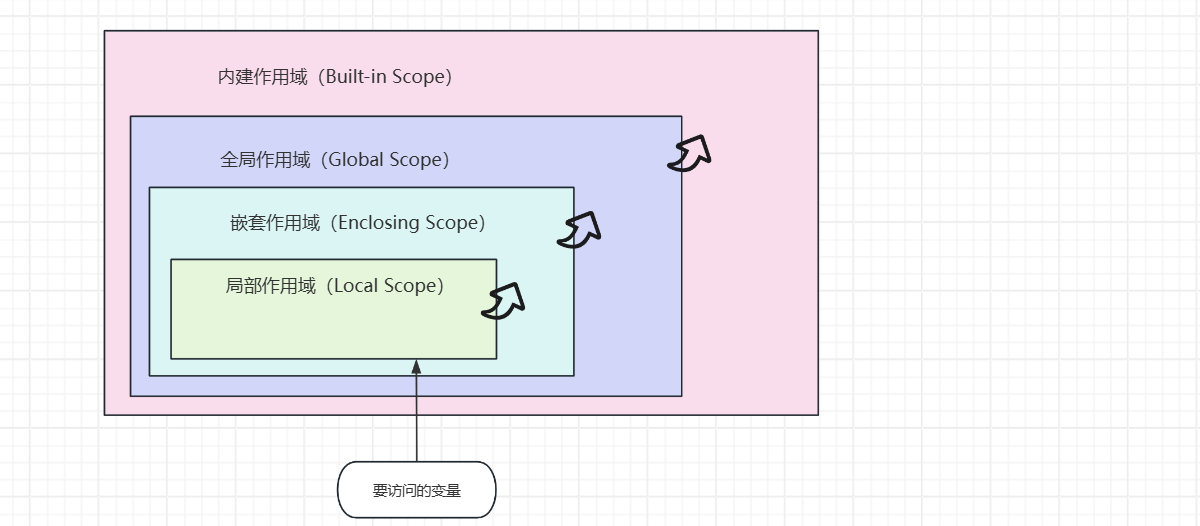
LEGB 是实际上就是四个作用域的英文单词的缩写,是Python的作用域查找规则,Python在多层代码嵌套结构下会按照 L -> E -> G -> B 的顺序依次查找变量名。
这个顺序有时候也被称之“作用域链”(Scope Chain)。如下图所示:
注意:
如果所有命名空间都未找到标记符名称,则会抛出
NameError异常。外层作用域下的代码无法访问内层作用域下的标记符名称,否则会抛出
NameError异常。
2.2.2.3 全局变量与局部变量¶
Python程序中一般也会按作用域下把变量操作的不同划分为2类,分别是全局变量(Global Variables)与局部变量(Local Variables)。
全局变量,函数或类的外部声明的变量,即全局作用域与内置作用域下的变量,其生命周期遵循对应所在作用域规则。
局部变量,函数或类的内部声明的变量。即嵌套作用域与内部作用域下的变量,其生命周期遵循对应所在作用域规则。
2.2.2.3.1 global¶
在函数中使用global,可以修改全局变量,代码:
count: int = 1
def a():
count = 'a函数里面'
def b():
global count # 告诉python,当前函数中使用的count,是个全局变量。
print(count)
count: int = 2
b()
print(count)
a()
print(count)
2.2.2.3.2 nonlocal¶
在函数中使用nonlocal,可以修改到父作用域的局部变量,代码:
count: int = 1
def a():
count: int = 2
def b():
nonlocal count # 告诉python,当前函数中使用的count,是外部作用域的局部变量
count = 3
print(count)
b()
a()
print(count)
2.2.2.3.3 错题集¶
例1,代码:
num: int = 10
def func1():
num += 20 # 赋值运算,为什么会报错?UnboundLocalError: cannot access local variable 'num' where it is not associated with a value
print(f"num={num}")
func1()
print(f"num={num}")
错误分析与说明:
错误提示:UnboundLocalError: cannot access local variable 'num' where it is not associated with a value
错误翻译:未绑定本地错误:无法访问未与值关联的本地变量“num”
错误分析:
num += 20 等价于num = num + 20
加法赋值属于先加后赋值,当前作用域会认为,num+20的这行代码执行之前num就存在了,但是实际上num是在加法运算之后才出现在当前作用域下的,所以未定义先使用肯定就报错了。
例2,代码:
count: int = 1
def a():
count: int = 2
def b():
nonlocal count
count: int = 3 # SyntaxError: annotated name 'count' can't be nonlocal
print(count)
b()
a()
print(count)
错误分析与说明:
错误提示:SyntaxError: annotated name 'count' can't be nonlocal
错误翻译:语法错误:带类型注解(annotated )的名称“count”不能是非本地(nonlocal)的。
错误分析:
count: int = 3 用于声明变量,在变量首次出现在作用域下才可以使用,
当前作用域会认为,count这个变量在代码执行之前count就存在于外部作用域了,所以语法冲突了因此报错。
2.2.3 栈帧空间¶
栈帧空间(Stack Frame)是Python函数执行时的动态创建的数据结构,也叫函数的执行上下文(Context)空间,在函数调用时创建,在函数执行结束时销毁,由局部命名空间和函数运行状态组成,即函数执行时所产生的信息与状态,如:局部变量、参数、函数调用处的地址等信息。
命名空间(Namespace)、作用域(Scope) 和 栈帧空间(Stack Frame) 是Python 中3个密切相关但不同的内容,它们共同决定了Python程序中变量、函数和数据对象的可见性、生命周期以及程序的执行流程。
2.3 匿名函数¶
也叫 lambda 表达式,又称匿名函数,常用来表示内部仅包含 1 行表达式的函数。如果一个函数的函数体仅有 1 行表达式,则该函数就可以用 lambda 表达式来代替。属于运行时声明的函数。
lambda 表达式的语法格式如下:
其中,定义 lambda 表达式,必须使用 lambda 关键字;[list] 作为可选参数,等同于定义函数是指定的参数列表;value 为该表达式的名称。
可以这样理解 lambda 表达式,其就是简单函数(函数体仅是单行的表达式)的简写版本。相比函数,lambda 表达式具有以下 2 个优势:
- 对于单行函数,使用 lambda 表达式可以省去定义函数的过程,让代码更加简洁;
- 对于不需要多次复用的函数,使用 lambda 表达式可以在用完之后立即释放,提高程序执行的性能。
data1: list = [1, "2", "C", "D", "A"]
# data1.sort() # 会报错,因为列表中的成员类型不一样。
data2: list = [1, "2", "C", "D", "A"]
# data2.sort()
list.sort(key= lambda x: str(x))
print(list)
2.4 一等公民¶
概念出处:
一等公民,也叫叫 first-class elements (一等元素或一等对象),是由 Christopher Stracey(克里斯托弗·斯特雷奇,英国计算机科学家,阿兰·图灵的好基友)在1967年研究编程语言的语义时,探讨了函数作为“一等公民”的能力,即函数可以像普通数据(整数、浮点数、字符串、列表、字典、元组等)一样被传递、赋值和操作,而衍生出的概念。1985 年,两位麻省理工的教授, 哈尔·阿伯尔森(Harold Hal Abelson)和 杰拉尔德·瑟斯曼(Gerald Sussman),外加瑟斯曼的妻子 朱莉·瑟斯曼(Julie Sussman),出版了一本叫做《 Structure and Interpretation of Computer Programs》(译作:计算机程序的构造和解释,简称:SICP,计算机神书之一)的教科书中的第1.3.4章中明确定义了“一等公民”这个编程术语,内容如下:
In general, programming languages impose restrictions on the ways in which computational elements can be manipulated. Elements with the fewest restrictions are said to have first-class status. Some of the ‘‘rights and privileges’’ of first-class elements are: They may be named by variables. They may be passed as arguments to procedures. They may be returned as the results of procedures. They may be included in data structures.
所谓的“一等公民”是指代满足下述条件的程序实体:
| 必要条件 | 假设x为该程序实体 |
|---|---|
| 可赋值给变量,让变量代表它运行。 | 变量=x |
| 可作为函数的参数。 | 函数名(x) |
| 可作为函数结果返回。 | return x |
| 可包含在数据结构中,例如可以包含在列表等数据类型中作为成员存在。 | {"a":x} |
在 Python 中,“一等公民”(First-Class Citizen)指的是语言中的某种实体(如函数、类、模块等)具备与其他基本数据类型(如整数、字符串等)同等的操作权限。
总而言之,就是在Python中,我们可以把函数像普通变量一样任意地使用。包括赋值给变量以及作为其它函数的参数和返回值。
因为Python中的整数、浮点数、字符串、列表、字典、元组、函数、类本身、类型本身以及模块等都是对象。所以函数和整数、字符串、列表、字典和元组等基础数据结构的地位是平等的。
def add(x: int, y: int)-> int:
return x + y
def sub(x: int, y: int)-> int:
return x - y
def div(x: int, y: int)-> int:
return x / y
def mul(x: int, y: int)-> int:
return x * y
def calc(x: int, y: int, func: callable)->...:
return func(x, y)
ret: int = calc(10, 20, add)
print(ret)
ret: int = calc(10, 20, sub)
print(ret)