文件操作¶
1. 前置知识¶
1.1 I/O操作¶
在前面通过学习input和print这两个函数,我们了解了Python程序与外部世界之间如何进行数据交换,即接收用户的输入数据与打印数据给用户查看。
在python中,具有输入/输出操作,用于程序与外部世界之间进行数据交换的功能,我们统称为“I/O”,即“Input/Ouput”的简写 。
I/O操作在python中一共有3种不同类型:
- 标准 I/O,也叫标准输入/标准输出,指Python程序与标准输入(键盘)、标准输出(显示器)等设备之间的数据交换。
- 文件 I/O,指Python程序与文件之间的数据交换。
- 网络 I/O 指Python程序与网络之间的数据交换。
前面学习的标准I/O操作相关函数实际上并不能让我们把数据长期保存到计算机中,因此当Python程序执行结束以后,之前操作输入的数据就会丢失,再次运行Python程序就会还原。
所以,我们如果需要长期而稳定的保存数据下来,就需要通过文件I/O操作把数据保存到文件中,它可以长期而稳定地保存数据,通常也叫对数据进行持久化存储。
文件操作对编程语言非常重要,如果数据不能持久化存储,信息技术也就失去了意义。
1.2 文件操作¶
文件(file),就是可以长期存储在存储设备上的一段数据的集合。所谓存储设备,即移动硬盘、固态硬盘、U盘等硬件设备。
根据文件存储的字符的不同格式,可分为:
- 文本文件,也叫字符流(string steam),内容是文本字符,人类可读,例如:main.py,data.txt等等。
- 二进制文件,也叫字节流(bytes steam),内容是二进制格式的字节串,人类不可读,例如:python.exe,data.zip,avatar.png等等。
除此之外,根据文件存储的内容的不同格式或不同用途,也可分为:
- 图片文件,例如:xxx.png,xxx.gif,xxx.jpg等等。
- 音频文件,例如:xxx.mp3,xxx.wav等等。
- 视频文件,例如:xxx.mp4,xxx.avi等等。
补充:
- 文件的完整名称由2部分构成:文件名+文件扩展名。
如:xxx.mp4中xxx就是文件名,mp4就是文件扩展名,也叫文件后缀。
- 文件后缀仅仅是为了方便在不打开文件时方便了解文件的内容格式而已,并非是必要的。
例如:我们通常创建的python文件,如main.py实际上不加.py也可以让python解释器执行,因为重点不是扩展名而是内容。
在Python中除了默认提供的文件操作函数以外,用于文件或目录操作的常用模块有:
-
内置模块:os(操作系统模块),sys(解释器), shutil(shell工具),pathlib(目录操作),fileinput(批量文件操作)、tempfile(临时文件或目录)、zipfile(压缩文件)、 tarfile(归档文件)、json(json文件)、pickle(二进制压缩)等。
-
第三方模块:PyYAML(YAML文件)、pandas(数据分析与多文件读写)、openpyxl(Excel文件)、xlsxwriter(Excel文件)、watchdog(文件监控)
上述所列模块都是工作中常用的模块,我们在后续课程中基本都会学习到,但现在我们先学习Python解释器内置的文件操作函数先,这是后续所有文件操作的基础。
2. 快速入门¶
2.1 打开文件¶
Python解释器内置了一个open()函数可以用于创建一个指定文件,如果文件已存在,则表示打开该文件。提供了3种用法:
# 1. 直接指定文件路径,打开文件,如果文件不存在,则报错 FileNotFoundError。
file: ... = open(file_name: str)
# 2. 以指定访问模式打开文件。
file: ... = open(file_name: str, access_mode: str="r")
# 3. 以指定访问模式、指定编码格式打开文件
file: ... = open(file_name: str, encoding: str=None)
参数选项:
file_name:文件路径,就是文件在计算机中的存储位置。
access_mode:打开文件的访问模式,不同的访问模式可以提供给开发者对文件进行不同的操作。默认为只读模式,即只能读取文件的内容,但是不能修改文件内容。
encoding:编码类型,常用编码字符:utf-8, gbk。
2.2 读写文件¶
我们先创建一个1.txt文件保存在当前目录下,1.txt,内容如下:
编写代码读取上面的内容:
# 打开指定文件
file: ... = open('1.txt')
# 通过上面的file提供的read()方法来读取内容。
content: str = file.read()
# 对读取到的内容进行处理
print(content)
上面操作中,我们手动创建data.txt并给它写入内容,然后在python代码中读取了它的内容,那如果我们不想手动创建手动写入内容的话,可以使用以下代码来完成。
OK,执行上面的代码以后,我们可以看到当前目录下就会自动出现了一个新的data2.txt文件,内容为"hello moluo!!!!"。
2.3 关闭文件¶
# 打开文件,使用w模式打开文件,当文件不存在,会自动创建,如果文件存在,则截断文件所有内容【清空内容】
file: ... = open("2.txt", "w")
# 写入内容
file.write("hello world\n")
file.write("hello moluo\n")
file.write("hello python")
# 关闭文件
file.close()
3. 基本概念¶
3.1 文件路径¶
路径(path),表示连接两个点或实体之间的路线或轨迹,在网络中,一般指代文件路径,表示一个文件在互联网/磁盘中的具体存储位置。
在编程语言中,文件路径的写法如下:
-
根据目标文件是否在当前计算中可以分2种:
-
本地路径(Local Path),指文件在当前计算机上的路径,可以细分为相对路径与绝对路径。
例如:安装在当前计算机中的Python解释器所在路径:
C:/tools/python3/python.exe -
网络路径(Network Path),指文件或资源在网络上的位置,以网络协议(如HTTP、FTP等)开头编写的路径。注意:open()无法操作网络路径下的文件。
例如,python官方文档所在路径:
https://docs.python.org/zh-cn/3.13/index.html -
根据路径的起始位置不同,还可以分2种:
-
绝对路径(Absolute Path),以根目录作为路径开始位置指向到目标文件的路径。如,
C:/tools/python3/python.exe。windows系统的绝对路径起始位置是从
盘符开始的,如,C:/或者 D:/ 。因此不同盘符下的文件存储不同的绝对路径。windows以外的其他操作系统的绝对路径起始位置是从
/开始的。例如:/bin/cd 或者 /usr/sbin/chown,/bin/python -
相对路径(Relative Path),以当前工作目录作为开始位置指向到目标文件的路径。如:
./data.txt或者../day01/main.py。
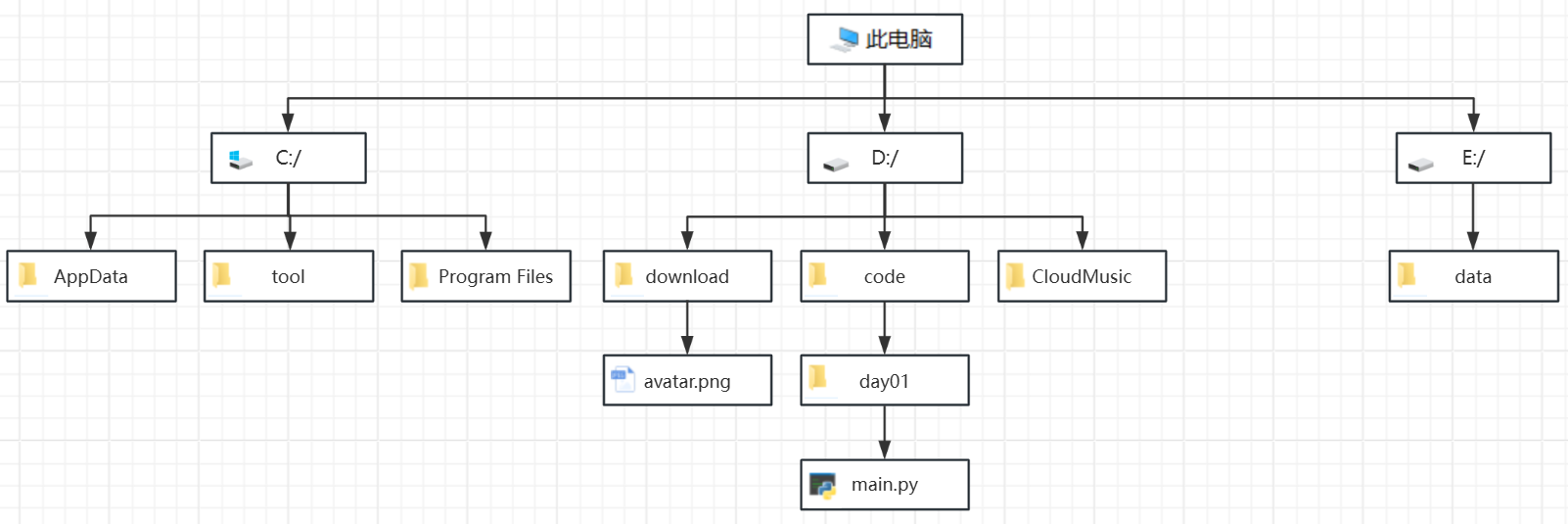
注意:在windows系统下,在不同盘符下的2个文件是无法使用相对路径来表示的。root根目录开始
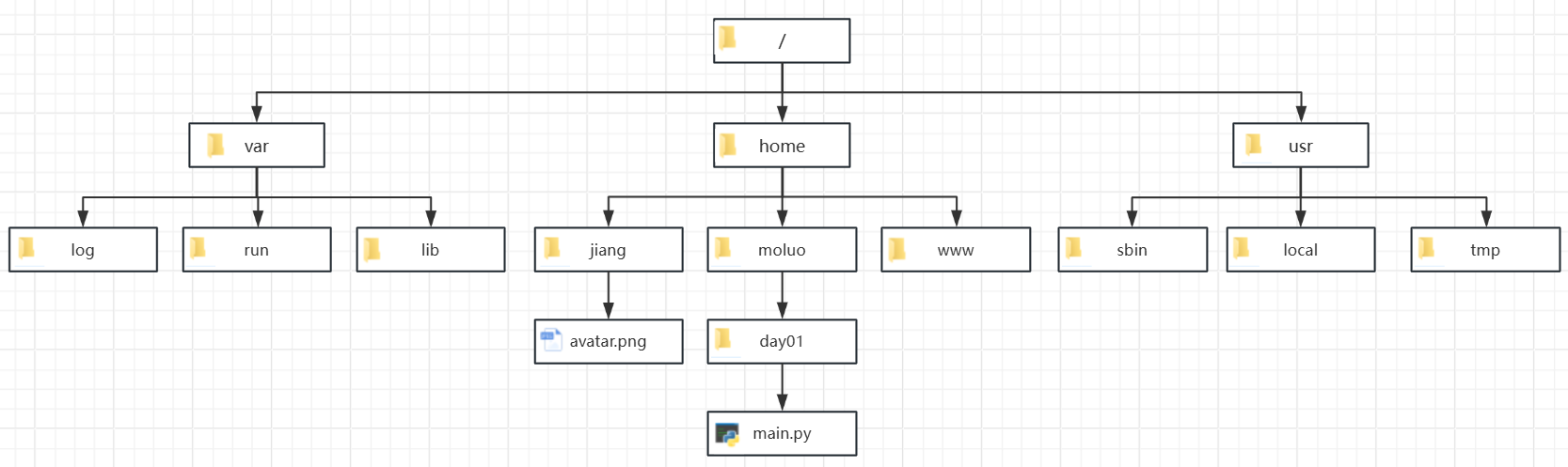
在路径编写过程中,从起始位置到目标位置,一般会经过不同的文件夹(目录,directory),因此为了区分与表示这些文件夹之间的包含关系,因此需要使用/或者\作为目录分隔符。除了windows系统以外其他系统则仅支持/,而且\在编程语言中往往充当转义字符的前缀,因此编写文件路径时,务必使用/。
/ 在文件目录中,表示目录分隔符,用于表达文件和目录之间的包含关系的
. 在文件目录中,表示当前目录,是一种以当前文件的位置作为参考值,表达文件/目录所在位置的一种相对表达方式,例如生活中的,我的对面,我的隔壁,
.. 在文件目录中,表示父级目录(上级目录),也是以当前文件的位置作为参考值
/目录/文件名 顶级目录下(顶级路径下)
./1.txt 当前目录下的1.txt文件
../2.txt 父级目录下的2.txt文件
../../3.txt 上2级目录下的3.txt文件
../file/4.txt 父级目录下的file目录下的4.txt文件
/3.txt 当前系统根目录(windows下表示当前系统盘符下)的3.txt
3.2 访问模式¶
Python程序对文件中的基本操作,存在读取、写入、追加写入三种操作模式:
- 读取:只读,read,简写r,表示从指定文件中读取内容。
- 写入:只写,write,简写w,表示把指定内容写入到指定文件中。
- 追加写入:append,简写a,表示把指定内容追加写入到指定文件末尾中。
| 访问模式 | 功能 | 内容格式 | 当文件不存在时 | 指针位置 | 是否截断清空内容 | 补充说明 |
|---|---|---|---|---|---|---|
| r | 读 | str | 会报错 | 开头 | 默认模式 | |
| w | 写 | str | 会自动创建 | 开头 | ✔ | |
| a | 追加写入 | str | 会自动创建 | 末尾 | ||
| rb | 读 | bytes | 会报错 | 开头 | 不能设置编码 | |
| wb | 写 | bytes | 会自动创建 | 开头 | ✔ | 不能设置编码 |
| ab | 追加写入 | bytes | 会自动创建 | 末尾 | 不能设置编码 | |
| r+ | 读、写 | str | 会报错 | 开头 | ||
| w+ | 读、写 | str | 会自动创建 | 开头 | ✔ | |
| a+ | 读、追加写入 | str | 会自动创建 | 末尾 | ||
| rb+ | 读、写 | bytes | 会报错 | 开头 | 不能设置编码 | |
| wb+ | 读、写 | bytes | 会自动创建 | 开头 | ✔ | 不能设置编码 |
| ab+ | 读、追加写入 | bytes | 会自动创建 | 末尾 | 不能设置编码 |
注意:
-
普通文本文件内容也可以使用二进制模式进行操作。
-
基于w写入模式打开的文件,原有内容会被截断清除(即清空内容),如:w,w+,wb,wb+。
-
基于a追加模式打开的文件,文件读写数据的光标会位于文件末尾,此时无法读取文件内容,如:a,a+,ab,ab+。
-
基于r只读模式打开一个不存在的文件都会报错,如:r,r+,rb,rb+。
-
文件指针就是我们平时输入文件时,一直闪烁的竖线。

4. 文件对象¶
在现实世界中,水对于我们来说就是一种资源,当我们需要水时就需要凿井,然后通过水管来取水。如果把计算机理解为一个虚拟世界的话,那么存储在其内部的文件对于我们用户而言就跟水一样也是一种资源,我们每次要通过程序对文件进行操作,也需要一条虚拟水管来完成。这个虚拟的水管,在计算机中就称之为"管道对象" 也可以叫"句柄", "连接", "通道对象"等。
open函数执行的结果是一个句柄对象。通过使用句柄对象提供的方法或属性,我们就可以完成文件的读写,打开与关闭等操作了。
from typing import TextIO, BinaryIO
file: TextIO = open("1.txt", "r")
print(file, type(file)) # <_io.TextIOWrapper name='1.txt' mode='r' encoding='cp936'> <class '_io.TextIOWrapper'>
file2: BinaryIO = open("1.txt", "rb")
print(file2, type(file2)) # <_io.BufferedReader name='1.txt'> <class '_io.BufferedReader'>
4.1 常用属性¶
| 屬性名 | 描述 |
|---|---|
| file.name | 获取当前打开文件的文件名 |
| file.closed | 获取当前文件的关闭状态 |
| file.mode | 获取当前打开文件的访问模式,默认是cp936模式 |
代码:
from typing import TextIO
file: TextIO = open("1.txt", "r")
print(file.closed) # False,表示文件处于打开状态
print(file.mode) # r
# 只有文件处于打开状态,我们才可以通过文件对象file去读取或写入内容到文件,否则无法操作。
content: str = file.read()
print(content)
# 关闭文件
file.close()
print(file.closed) # True,表示文件已关闭
content = file.read() # 关闭文件以后,无法继续操作文件,会报错。
4.2 常用方法¶
| 方法 | 描述 |
|---|---|
| file.read([n=-1]) | 读取文件内容的n个字符内容。如果没有设置n则默认n为-1,表示读取文件中的全部内容。 |
| file.readline([limit=-1]) | 按行读取文件中一行的limit个字符内容,如果没有设置limit则默认读取整行内容。 |
| file.readlines() | 按行读取文件内容,结果为列表,列表的成员是文件的每一行内容。 |
| file.write(str: string|bytes) | 写入文件内容,将数据写入被打开的文件中。 |
| file.writelines(seq) | 把列表中的成员数据写入到文件中,就是一次性写入多行内容。 |
| file.tell() | 获取当前文件中读写数据的光标(指针)所在位置。 1. 基于r或r相关模式打开的文件,默认指针位置是0,表示文件开头。 2. 基于a或a相关模式打开的文件,默认指针位置在文件末尾。 3. 执行完file.read()以后,光标位置是在读取内容的后面,a相关模式除外。 |
| file.seek(offset: int) | 设置文件读写数据的光标(指针)到指定的offset指定位置。 |
| file.truncate(size: int = None) | 把文件裁成指定大小。文件必须以写方式打开,但w和w+除外。 |
| file.flush() | 把缓冲区的内容写入硬盘的文件中。 程序写入内容到文件时并不是逐行代码逐行写入,而是先把写入文件的数据先保存到了内存的缓冲区中。 |
| file.writable() | 判断当前打开文件是否可写。 |
| file.readable() | 判断当前打开文件是否可读。 |
5. 详细操作¶
准备工作,创建一个1.txt文件,并保存内容如下:
君不见,黄河之水天上来,奔流到海不复回。
君不见,高堂明镜悲白发,朝如青丝暮成雪。
人生得意须尽欢,莫使金樽空对月。
天生我材必有用,千金散尽还复来。
烹羊宰牛且为乐,会须一饮三百杯。
岑夫子,丹丘生,将进酒,杯莫停。
与君歌一曲,请君为我倾耳听。
钟鼓馔玉不足贵,但愿长醉不复醒。
古来圣贤皆寂寞,惟有饮者留其名。
陈王昔时宴平乐,斗酒十千恣欢谑。
主人何为言少钱,径须沽取对君酌。
五花马,千金裘,呼儿将出换美酒,与尔同销万古愁。
5.1 读写文件¶
""""""
from typing import TextIO, BinaryIO
"""
读取数据
file.read(n=-1) # 读取文件所有内容,如果有指定参数选项n,则表示本次读取数据只读取n个字符
file.readline() # 读取文件的一行内容
"""
# 按字符串读取文件内容
file: TextIO = open("1.txt", "r", encoding="utf-8")
data: str = file.read(5) # 本次读取5个字符
print(data)
data: str = file.read(15)
print(data) # 在上一次的进度上,再次读取5个字符
data: str = file.read()
print(data) # 读取剩余内容的全部
file.close()
"""按行读取文件内容"""
file: TextIO = open("1.txt", "r", encoding="utf-8")
content: str = file.readline()
print(content)
content: str = file.readline()
print(content)
content: str = file.readline()
print(content)
# 读取大文件可以使用这个方式
file: TextIO = open("1.txt", "r", encoding="utf-8")
while True:
content: str = file.readline()
if not content: # 切记:要加判断,如果读不到内容了就退出循环
break
print(content)
"""一次性把文件所有内容以列表方式,逐行读取返回"""
# 大文件千万不要这么读取, 小文件可以
file = open("1.txt", "r", encoding="utf-8")
print( file.readlines() )
# ['君不见,黄河之水天上来,奔流到海不复回。\n', '君不见,高堂明镜悲白发,朝如青丝暮成雪。\n', '\n', '人生得意须尽欢,莫使金樽空对月。\n', '天生我材必有用,千金散尽还复来。\n', '\n', '烹羊宰牛且为乐,会须一饮三百杯。\n', '岑夫子,丹丘生,将进酒,杯莫停。\n', '与君歌一曲,请君为我倾耳听。\n', '\n', '钟鼓馔玉不足贵,但愿长醉不复醒。\n', '古来圣贤皆寂寞,惟有饮者留其名。\n', '陈王昔时宴平乐,斗酒十千恣欢谑。\n', '主人何为言少钱,径须沽取对君酌。\n', '五花马,千金裘,呼儿将出换美酒,与尔同销万古愁。']
"""
写入数据
file.write(string | bytes) # 把字符串/bytes类型数据写入到文件中
file.writeline(seq) # 把序列类型中数据逐行写入到文件(序列类型中的成员必须是字符串)
"""
# 写入一个数据(字符串/bytes)
file: TextIO = open("2.txt", "w")
file.write("hello moluo")
file.close()
# 写入二进制数据,文本也可以转换成二进制写入,但是工作中更多的是图片/网络信息/视频/音频/压缩包等二进制比较多
file: BinaryIO = open("2.txt", "wb")
file.write("hello world".encode())
file.close()
"""把序列类型中的数据逐行写入"""
# 使用write把列表中的数据逐行写入
data: list[str] = ['君不见,黄河之水天上来,奔流到海不复回。', '君不见,高堂明镜悲白发,朝如青丝暮成雪。', '人生得意须尽欢,莫使金樽空对月。', '天生我材必有用,千金散尽还复来。', '烹羊宰牛且为乐,会须一饮三百杯。', '岑夫子,丹丘生,将进酒,杯莫停。', '与君歌一曲,请君为我倾耳听。', '钟鼓馔玉不足贵,但愿长醉不复醒。', '古来圣贤皆寂寞,惟有饮者留其名。', '陈王昔时宴平乐,斗酒十千恣欢谑。', '主人何为言少钱,径须沽取对君酌。', '五花马,千金裘,呼儿将出换美酒,与尔同销万古愁。']
file: TextIO = open("5.txt", "w", encoding="utf-8")
for item in data:
file.write(f"{item}\n")
file.close()
data: list[str] = ['君不见,黄河之水天上来,奔流到海不复回。', '君不见,高堂明镜悲白发,朝如青丝暮成雪。', '人生得意须尽欢,莫使金樽空对月。', '天生我材必有用,千金散尽还复来。', '烹羊宰牛且为乐,会须一饮三百杯。', '岑夫子,丹丘生,将进酒,杯莫停。', '与君歌一曲,请君为我倾耳听。', '钟鼓馔玉不足贵,但愿长醉不复醒。', '古来圣贤皆寂寞,惟有饮者留其名。', '陈王昔时宴平乐,斗酒十千恣欢谑。', '主人何为言少钱,径须沽取对君酌。', '五花马,千金裘,呼儿将出换美酒,与尔同销万古愁。']
file: TextIO = open("5.txt", "w", encoding="utf-8")
file.writelines(data)
file.close()
5.2 文件指针管理¶
from typing import TextIO, BinaryIO
"""
文件操作过程中的指针(光标)管理
file.tell() # 查看当前文件中指针位置
file.seek(offset) # 控制移动当前文件中指针的位置
注意:
r模式打开文件,指针在开头
w模式打开文件,指针在开头
a模式打开文件,指针在末尾
"""
file: TextIO = open("1.txt", "r", encoding="utf-8")
point: int = file.tell() # 读取文件指针位置,不会影响文件指针的位置
print(point) # 0
content: str = file.read(5) # 读取5个字符,读取/写入数据到文件时,文件指针会随着操作而移动
print(content) # 君不见黄河
point: int = file.tell()
print(point) # 15 ctrl+D 复制光标所在 ctrl+x 剪切光标所在行
content: str = file.read(5)
print(content) # 之水天上来
"""
上面读取了5个中文以后,文件指针从0移动到了15,原因是因为文件指针是按照字符本身在编码中的字节长度来计算的。
"""
file: TextIO = open("1-1.txt", "r", encoding="gbk")
point: int = file.tell() # 读取文件指针位置,不会影响文件指针的位置
print(point) # 0
content: str = file.read(5) # 读取5个字符,读取/写入数据到文件时,文件指针会随着操作而移动
print(content) # 君不见黄河
point: int = file.tell()
print(point) # 10 ctrl+D 复制光标所在 ctrl+x 剪切光标所在行
content: str = file.read(5)
print(content) # 之水天上来
"""使用seek在操作文件过程中移动指针的位置"""
# 例如,以a+模式打开一个文件,就可以对文件进行读写,但是因为a模式的原因,指针会在文件末尾。
# 此时,如果希望让指针回到最开始位置,就可以使用seek
file: TextIO = open("6.txt", "a+", encoding="utf-8")
content: str = file.read()
print(content)
point: int = file.tell()
print(point) # 183
# 把指针位置移动到文件开头
file.seek(0)
point: int = file.tell()
print(point) # 0
content: str = file.read(5)
print(content) # 君不见黄河
point: int = file.tell()
print(point) # 15
# 再次把指针位置移动到文件开头
file.seek(0)
point: int = file.tell()
print(point) # 0
content: str = file.read(5)
print(content) # 君不见黄河
point: int = file.tell()
print(point) # 15
# a+模式可以让我们写入内容,因为a模式属于追加内容的原因,所以如果写入内容,则内容会被追加文件末尾
content: str = "(又大又长的黄河)"
file.write(content)
point: int = file.tell()
print(point) # 229
5.3 冲刷缓存区¶
所谓缓冲区,就是内存空间的一部分用于临时保存数据的区域,这部分内存空间只保存程序运行过程中的输入和输出数据。
from typing import TextIO
"""
在文件操作过程中,因为内存中的信息处理速度要远远高于硬盘设备的处理速度,
所以如果内存中程序运行的结果如果和硬件处理速度保持一致,就会让内存/CPU存在极大浪费
所以,内存中高速运行程序时,会把程序执行的结果保存到内存的暂存区域(缓冲区)里面。
后续操作系统会自动往暂存区域里面提取程序的结果进行进一步处理。
"""
file: TextIO = open("7.txt", "w")
file.write("hello")
# "hello"这段文件目前还在缓冲区里面,所以我们如果打开文件,
# 在文件管道对象关闭之前,是看不到上面的"hello"
input("让程序等到用户输入内容以后才结束")
file.close()
# 默认情况下,只有在关闭文件管道对象时,才会把程序运行的结果冲刷出缓冲区,
# 如果出现程序运行时,系统断电等问题,则会造成部分数据丢失。
"""
如果希望程序运行的结果,快速从缓冲区里面把数据冲刷出来。
可以使用file.flush()
"""
file: TextIO = open("7.txt", "w")
file.write("hello")
input("让程序停顿一下")
file.flush() # 冲刷缓存区,让数据不需要等待程序执行结束也可以提前写入到文件中。
file.write(" world!!!!!")
input("让程序停顿一下")
file.close() # 默认情况下,只有在关闭文件管道对象时,才会把程序运行的结果冲刷出缓冲区。
在以下几种情况下操作系统会把缓冲区的数据冲刷新出来: 1. 当文件关闭的时候自动刷新缓冲区 2. 当整个程序运行结束的时候自动刷新缓冲区 3. 当缓冲区写满了,也会自动刷新缓冲区 4. 手动刷新缓冲区 file.flush()就是手动调用
5.4 判断文件的可读可写状态¶
with open("9.txt", "w") as f:
ret: bool = f.writable() # True表示可写入数据到文件中
print(ret) # True
ret: bool = f.readable() # True表示可读取文件中的数据,False表示不能
print(ret) # False
5.5 写入复杂类型数据¶
import base64
from typing import TextIO, BinaryIO
"""方案1. 以代码格式把复杂数据写入到python程序中,以python模块引入到python中使用"""
# # 写入操作
# student_list: list[dict[str,str|int]] = [
# {"name": "小红", "age": 16, "gender": "女", "phone": "13312345567"},
# {"name": "小红", "age": 13, "gender": "男", "phone": "13312345567"},
# ]
#
# file: TextIO = open("student.py", "w", encoding="utf-8")
# code: str = f"student_list={str(student_list)}"
# file.write(code)
# file.close()
# # 导入上面的python中的student_list
# from student import student_list
# print(student_list)
# print(type(student_list))
"""方案2:通过json模块提供的函数,把复杂数据转换成json字符串,后续再把json字符串成原格式格式"""
import json
# # 把其他数据数据转换成json字符串
# data_list: list = [1, True, "中文"]
# data_json: str = json.dumps(data_list, ensure_ascii=False)
# print(data_json, type(data_json))
#
# # 把json字符串还原成原格式数据
# data_list: list = json.loads(data_json)
# print(data_list, type(data_list))
# # 写入操作
# student_list: list[dict[str,str|int]] = [
# {"name": "小红", "age": 16, "gender": "女", "phone": "13312345567"},
# {"name": "小红", "age": 13, "gender": "男", "phone": "13312345567"},
# ]
# file: TextIO = open("student.json", "w", encoding="utf-8")
# file.write(json.dumps(student_list, ensure_ascii=False))
# file.close()
# # 读取操作
# file: TextIO = open("student.json", "r", encoding="utf-8")
# student_str: str = file.read()
# print(student_str, type(student_str))
# student_list: list = json.loads(student_str)
# print(student_list, type(student_list))
"""方案3:基于方案2的改动,使用base64编码进行处理"""
# import base64
# res: str = base64.b64encode("中文".encode("utf-8")).decode("utf-8")
# print(res)
#
# data: str = "5Lit5paH"
# res: str = base64.b64decode(data).decode("utf-8")
# print(res)
# # 写入操作
# import base64
# student_list: list[dict[str,str|int]] = [
# {"name": "小红", "age": 16, "gender": "女", "phone": "13312345567"},
# {"name": "小红", "age": 13, "gender": "男", "phone": "13312345567"},
# ]
# file: BinaryIO = open("student.txt", "wb")
# code: str = json.dumps(student_list, ensure_ascii=False)
# data: bytes = base64.b64encode(code.encode("utf-8"))
# file.write(data)
# file.close()
# 读取操作
import base64
file: TextIO = open("student.txt", "r", encoding="utf-8")
content: str = file.read()
student_str = base64.b64decode(content).decode("utf-8")
student_list = json.loads(student_str)
print(student_list, type(student_list))
file.close()
5.6 基于with操作文件¶
with语句也叫上下文管理器,使用上下文管理器,可以在读写文件的时候,只需要关注于操作文件的代码编写,而不需要在意文件是否关闭了,因为with语句块在执行完以后,会自动执行file.close()方法,防止开发人员忘记关闭文件。
语法如下:
代码:
with open("student.txt","r") as file:
content: str = file.read()
print(content)
print(file.closed) # 在with语句缩进代码块内部,文件是一致没有被关闭的
print(file.closed) # 离开with缩进代码块以后,文件已经关闭。
6. 练习案例¶
6.1 备份文件操作¶
# 让用户指定要备份的文件
backup_file_name: str = input("请输入您要备份的文件名[包括路径]:")
# 备份文件的标记
backup_flag = '[备份]'
# 获取当前文件的文件名以及扩展名
dot_index: int = backup_file_name.rfind('.')
if dot_index > 0:
file_name: str = backup_file_name[:dot_index] # 文件名
extension: str = backup_file_name[dot_index:] # 扩展名
# print(f"file_name:{file_name},extension:{extension}")
# 组合新文件的完整文件名
new_file_name: str = f"{file_name}{backup_flag}{extension}"
else:
new_file_name: str = f"{backup_flag}{backup_file_name}"
print(f"new_file_name:{new_file_name}")
# 打开源文件,并以bytes读取内容
with open(backup_file_name, 'rb') as original_file:
# 打开新文件,并以bytes写入内容
with open(new_file_name, 'wb') as new_file:
# 不断读取文件中的内容,直到内容为空字符,就退出循环
while content := original_file.read(4):
new_file.write(content)
6.2 学生信息管理系统[持久化版本]¶
import json
welcome: str = "欢迎来到xx学生信息管理系统。"
menu_list: list[str] = [
"1. 查看学生信息",
"2. 添加学生信息",
"3. 修改学生信息",
"4. 删除学生信息",
"5. 退出信息系统",
]
question: str = "请输入要进行的操作序号(1-5):"
# 手动创建文件 student.txt
student_list = []
with open("student.txt", "r", encoding="utf-8") as file:
content: str = file.read()
if len(content) > 0:
student_list: list = json.loads(content)
while True:
print("* " * 32)
print(f"* {welcome: <52}*")
for menu in menu_list:
print(f"* {menu: <56}*")
print("* " * 32)
answer: str = input(question)
match answer:
case "1":
print("查看所有学生信息...")
print("- " * 56)
for index, student in enumerate(student_list):
if student == {}:
continue
print(f"{f"学号:{index+1}": <10} {f"姓名:{student['name']}": <14} {f"年龄:{student['age']}": <14} {f"性别:{student['gender']}": <10} 联系电话:{student['phone']}")
print("- " * 56)
case "2":
print("请输入要录入系统的学生信息...")
name: str = input("姓名:")
age: int = int(input("年龄:"))
gender: str = input("性别:")
phone: str = input("联系电话:")
student_list.append({"name": name, "age": age, "gender": gender, "phone": phone})
case "3":
print("更新学生信息...")
print("- " * 56)
for index, student in enumerate(student_list):
if student == {}:
continue
print(f"{f"学号:{index+1}": <10} {f"姓名:{student['name']}": <14} {f"年龄:{student['age']}": <14} {f"性别:{student['gender']}": <10} 联系电话:{student['phone']}")
print("- " * 56)
number: int = int(input("请输入要更新的学生序号:"))
student: dict = student_list[number-1]
name: str = input(f"姓名({student['name']}),如果不填写则默认不修改:")
age: str = input(f"年龄({student['age']}),如果不填写则默认不修改:")
gender: str = input(f"性别({student['gender']}),如果不填写则默认不修改:")
phone: str = input(f"联系电话({student['phone']}),如果不填写则默认不修改:")
if len(name) > 0:
student["name"] = name
if len(age) > 0:
student["age"] = age
if len(gender) > 0:
student["gender"] = gender
if len(phone) > 0:
student["phone"] = phone
case "4":
print("删除学生信息...")
print("- " * 56)
for index, student in enumerate(student_list):
if student == {}:
continue
print(f"{f"学号:{index+1}": <10} {f"姓名:{student['name']}": <14} {f"年龄:{student['age']}": <14} {f"性别:{student['gender']}": <10} 联系电话:{student['phone']}")
print("- " * 56)
number: int = int(input("请输入要删除的学生序号:"))
# 因为我们使用了列表的下标作为学号,因此不能直接通过删除成员来完成学生信息删除操作,而是应该替换成空字典来完成虚拟的删除
student_list[number-1] = {}
case "5":
print("成功退出信息系统...")
with open("student.txt", "w", encoding="utf-8") as file:
file.write(json.dumps(student_list, ensure_ascii=False))
break
print()
print()
6.2 下载图片¶
API接口地址:https://imgapi.cn/wiki.html,代码如下:
# 下载文件在python中,我们使用很多不同的模块来完成:
# 内置模块:urllib
# 第三方模块:requests
import time
from urllib import request
# 资源或者api的url地址
url: str = "https://imgapi.cn/api.php?fl=dongman&gs=images"
# 下载的数量
num: int = 10
for i in range(1, num+1):
print(f"开始下载第{i}张图片....")
with request.urlopen(url) as response:
with open(f"images/image-{i:02d}.png", "wb") as file:
file.write(response.read())
time.sleep(0.1)
print(f"第{i}张图片下载完成....")