04-并发编程进阶
并发编程进阶¶
守护进程¶
我们之前简单学过关于守护进程与守护线程,除了我们之前所学习的一个主进程/线程可以创建一个或多个守护进程的。
多个守护进程的使用
"""
默认主进程等待所有非守护进程,也就是子进程执行结束之后,在关闭程序,释放资源
守护进程在主进程的代码执行结束时, 就会自动关闭了,并非主进程的真正结束;
守护线程在主线程的代码执行结束时, 就会自动关闭了,并非主线程的真正结束;
"""
import time
from multiprocessing import Process
def daemon(i):
print(f"守护进程{i}启动了!!!")
while True:
time.sleep(1)
print(f"{i}:当前程序正常运行...")
def func(n):
print(f"子进程{n}启动了!")
time.sleep(3)
print(f"子进程{n}执行结束了!")
if __name__ == '__main__':
for i in range(2):
daemon_process = Process(target=daemon, args=(i,))
daemon_process.daemon = True
daemon_process.start()
p_list = []
for i in range(4):
process = Process(target=func, args=(i,))
process.start()
p_list.append(process)
for p in p_list: p.join()
print("主进程代码执行结束!")
生产者与消费者模型¶
生产者与消费者是一种面向对象的设计模式,主要作用是用于解决程序中生产和消费的供需场景问题的。举个例子,一般在生活中,像厂家生产衣服,顾客到店里买衣服,这就是一种供需的关系,那么在厂家与顾客之间,怎么完成这个供需的呢?是由厂家把商品发货给渠道(专卖店、地摊、超市),顾客通过渠道就可以消耗商品,这个流程除了适用于生活中的商品供需以外,在生活中也有其他的场景,例如:小明寄快递。
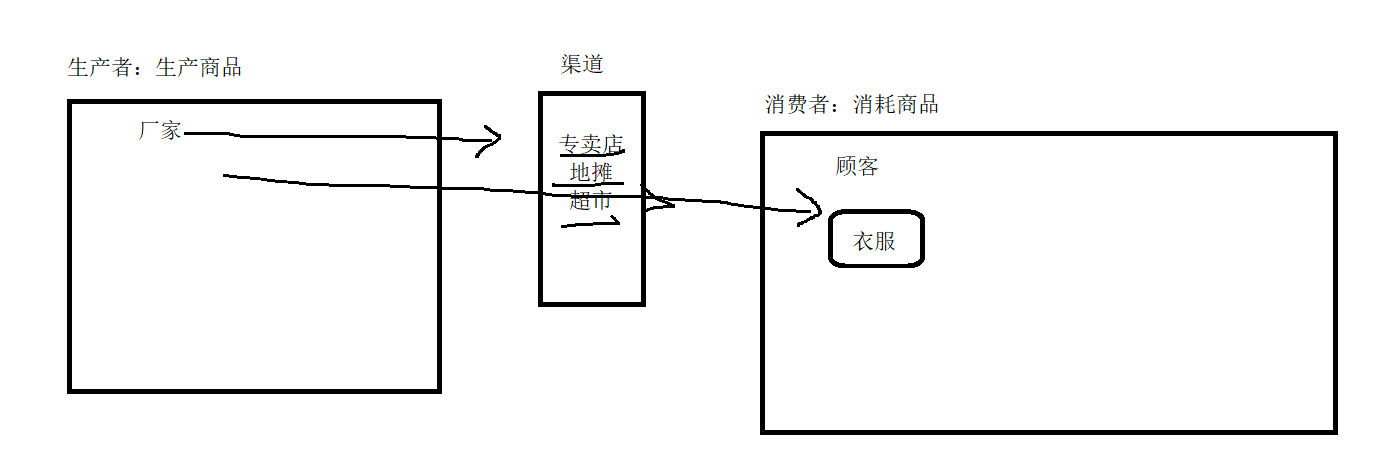
基于上面的生活场景,我们的程序中其实存在类似的场景,于是程序员总结了一个用于实现上面场景的设计模式:生产者与消费者模式(Producer-Consumer-Pattern)。
进程队列实现¶
import time, random, os
from multiprocessing import Process, Queue
# IPC:进程间的通信,可以使用Queue来完成
def consumer(q):
"""消费者"""
while True:
# 从队列中提取数据
res = q.get()
time.sleep(random.randint(1, 3))
print(f"{os.getpid()}吃{res}")
def producer(q):
"""生产者"""
for i in range(2):
time.sleep(random.randint(1, 3))
res = f"包子{i}"
q.put(res) # 把数据保存到队列中
print(f"{os.getpid()}生产了{res}")
if __name__ == '__main__':
# 相当于服务员
q = Queue()
# 生产者们: 即厨师
p1 = Process(target=producer, args=(q,))
p1.start()
# 消费者们: 即顾客
c1 = Process(target=consumer, args=(q,))
c1.start()
上面代码运行时,可以发现主进程永远不会结束,原因是生产者p1在生产完后就结束了,但是消费者c1在取空了队列q之后,则一直处于死循环中且卡在q.get()这一步。所以我们要解决下这个问题,而解决方式无非是让生产者在生产完毕后,往队列中再发一个结束信号,这样消费者在接收到结束信号后就可以break出死循环。
代码:
import time, random, os
from multiprocessing import Process, Queue
# IPC:进程间的通信,可以使用Queue来完成
def consumer(q):
"""消费者"""
while True:
# 从队列中提取数据
res = q.get()
if res is None: break # 当队列中提取到结束信息时,结束当前while循环
time.sleep(random.randint(1, 3))
print(f"{os.getpid()}吃{res}")
def producer(q):
"""生产者"""
for i in range(2):
time.sleep(random.randint(1, 3))
res = f"包子{i}"
q.put(res) # 把数据保存到队列中
print(f"{os.getpid()}生产了{res}")
if __name__ == '__main__':
# 相当于服务员
q = Queue()
# 生产者们: 即厨师
p1 = Process(target=producer, args=(q,))
p1.start()
# 消费者们: 即顾客
c1 = Process(target=consumer, args=(q,))
c1.start()
p1.join() # 这里阻塞等待所有的生产者全部提交任务
q.put(None) # 发送一个结束信号给队列中,让消费者进程能停止下来。
上面的代码表面上解决了主进程没有结束的问题,但是在多个生产者和多个消费者时还是会出现问题的,因为多个消费者,就需要多个结束信息。代码:
import time, random, os
from multiprocessing import Process, Queue
# IPC:进程间的通信,可以使用Queue来完成
def consumer(q):
"""消费者"""
while True:
# 从队列中提取数据
res = q.get()
if res is None: break # 当队列中提取到结束信息时,结束当前while循环
time.sleep(random.randint(1, 3))
print(f"{os.getpid()}吃{res}")
def producer(q):
"""生产者"""
for i in range(2):
time.sleep(random.randint(1, 3))
res = f"包子{i}"
q.put(res) # 把数据保存到队列中
print(f"{os.getpid()}生产了{res}")
if __name__ == '__main__':
# 相当于服务员
q = Queue()
# 生产者们: 即厨师
p_list = []
for i in range(5):
p = Process(target=producer, args=(q,))
p.start()
p_list.append(p)
# 消费者们: 即顾客
for i in range(10):
c1 = Process(target=consumer, args=(q,))
c1.start()
for p in p_list: p.join() # 这里阻塞等待所有的生产者全部提交任务
# 当出现多个生产者与消费者时,结束信号就要随着消费者的数量来发送。
for _ in range(10):
q.put(None) # 发送一个结束信息给队列中
改进版本,代码:
import time, random, os
from multiprocessing import Process, Queue
# IPC:进程间的通信,可以使用Queue来完成
def consumer(q):
"""消费者"""
while True:
# 从队列中提取数据
res = q.get()
if res is None: break # 当队列中提取到结束信息时,结束当前while循环
time.sleep(random.randint(1, 3))
print(f"{os.getpid()}吃{res}")
def producer(q):
"""生产者"""
for i in range(2):
time.sleep(random.randint(1, 3))
res = f"包子{i}"
q.put(res) # 把数据保存到队列中
print(f"{os.getpid()}生产了{res}")
def task(p_count, c_count):
# 相当于服务员
q = Queue()
# 生产者们: 即厨师
p_list = []
for i in range(p_count):
p = Process(target=producer, args=(q,))
p.start()
p_list.append(p)
# 消费者们: 即顾客
for i in range(c_count):
c1 = Process(target=consumer, args=(q,))
c1.start()
for p in p_list: p.join() # 这里阻塞等待所有的生产者全部提交任务
# 当出现多个生产者与消费者时,结束信号就要随着消费者的数量来发送。
for _ in range(c_count):
q.put(None) # 发送一个结束信息给队列中
if __name__ == '__main__':
task(3,3)
共享进程队列实现[了解]¶
上面实现的生产者与消费者模型,我们还可以使用JoinableQueue进行代码改进。JoinableQueue可以创建可连接的共享进程队列,这就像是一个Queue对象,但JoinableQueue队列允许项目的使用者通知生产者项目已经被成功处理。通知进程是使用共享的信号和条件变量来实现的。
from multiprocessing import Process, JoinableQueue
import time, random, os
def consumer(jq):
while True:
res = jq.get()
time.sleep(random.randint(1, 3))
print(f"{os.getpid()}吃{res}")
jq.task_done() # 向q.join()发送一次信号, 证明一个数据已经被取走了
def producer(jq):
for i in range(3):
time.sleep(random.randint(1, 3))
res = f"包子{i}"
jq.put(res)
print(f"{os.getpid()}生产了{res}")
jq.join() # 生产完毕,使用此方法进行阻塞,直到队列中所有项目均被处理。
def task(p_count, c_count):
jq = JoinableQueue()
# 生产者们: 即厨师
p_list = []
for i in range(p_count):
p = Process(target=producer, args=(jq,))
p.start()
p_list.append(p)
# 消费者们: 即顾客
for i in range(c_count):
c = Process(target=consumer, args=(jq,))
c.daemon = True
c.start()
# 开始
for p in p_list:
p.join()
print('主进程')
if __name__ == '__main__':
task(3,3)
进程间的数据共享[了解]¶
前面的学习中,我们知道多进程间的数据是独立在不同内存的,而线程之间的数据是共享。那如果我们希望让进程间也能实现数据共享呢,怎么做?是的,我们可以基于文件来完成进程间的数据共享。但对于我们手动操作文件来记录进程间的共享数据,这个功能,实际上python里面的multiprocessing模型已经内置实现了,那就是Manager对象。
基本使用
from multiprocessing import Process, Manager
def func(data):
data["count"] -= 1
if __name__ == "__main__":
# 设置进程间要共享的数据
manager = Manager()
data = manager.dict({"count": 100}) # 表示在多个子进程之间共享一个字典数据
p_list = []
for i in range(100):
p = Process(target=func, args=(data,))
p.start()
p_list.append(p)
# 等待每一个进程执行完毕
for p in p_list: p.join()
print(data)
虽然上面实现了数据共享,但是在进程数量多了的时候,就会出现数据不一致问题,所以需要加锁保证数据安全。代码:
from multiprocessing import Process, Manager, Lock
def func(data, lock):
with lock:
data["count"] -= 1
if __name__ == "__main__":
# 设置进程间要共享的数据
manager = Manager()
data = manager.dict({"count": 100}) # 表示在多个子进程之间共享一个字典数据
lock = Lock()
p_list = []
for i in range(100):
p = Process(target=func, args=(data, lock))
p.start()
p_list.append(p)
# 等待每一个进程执行完毕
for p in p_list: p.join()
print(data)
进程间共享数据使用不当时,特别是引用类型的数据(字典,列表,对象),容易导致出现错误而且不容排查,尽量少用。
信号量¶
前面的学习中,对于多个进程操作同一个共享数据,我们使用了一把进程锁Lock,可以实现在同一时间只有一个进程可以修改共享资源。但如果我们要实现同一时间允许多个进程上多把锁呢?此时,我们会使用进程的RLock(递归锁)。但是如果我们要实现同一时间内允许多个进程同时修改多个共享数据而且还要加锁呢?RLock不行了,因为它只允许同一时间只有一个进程或线程修改数据,此时,我们就需要使用到信号量(Semaphore)了。
信号量就是一个计数器couter,本质上就是一把锁,内部的实现原理是基于计数器+锁实现的,它允许同时给1个或多个进程上锁,当资源释放时计数器就会递增,当资源占用时计数器就会递减,多个进程可以通过操作信号量,达到同步执行的目的。注意:信号量不仅在进程模块multiprocessing中存在,而且threading模块中也有,作用一样,只是针对的对象不一样。
举个栗子,假设要实现一个商场的停车场运作程序,假设停车场只有4个车位,一开始所有车位都是空的,不断有顾客开车过来,假设一共有10辆车,那么我们就不能直接让10辆车都开进停车场了,必须有空位才能放车进去。代码:
import random
import time
from multiprocessing import Process, Semaphore
# from threading import Thread, Semaphore
def parking_lot(car, semaphore):
"""停车场"""
# semaphore.acquire()
# print(f"{car}进入停车场,目前停车位:{semaphore.get_value()}")
# # 因为我们都不知道顾客会停留在里面多久,所以我们使用随机数模拟这个停留过程
# time.sleep(random.randrange(4, 10))
# print(f"P{car}离开停车场,目前停车位:{semaphore.get_value()+1}")
# semaphore.release()
with semaphore:
print(f"{car}进入停车场,目前停车位:{semaphore.get_value()}")
# 因为我们都不知道顾客会停留在里面多久,所以我们使用随机数模拟这个停留过程
time.sleep(random.randrange(4, 10))
print(f"{car}离开停车场,目前停车位:{semaphore.get_value()+1}")
if __name__ == "__main__":
# 最多允许4个进程同时上锁
semaphore = Semaphore(4)
# 模拟10个顾客开车进来
for i in range(10):
# 顾客什么时候来的我们也不清楚,所以模拟下这个时间过程
time.sleep(random.randint(1, 5))
p = Process(target=parking_lot, args=(f"car-{i}", semaphore))
p.start()
事件¶
多进程模块multiprocessing与多线程threading模块提供了事件(Event )可以用来实现进程间/线程间的同步通信。运行机制是通过定义了一个多个进程共享的全局标记Flag,如果Flag值为 False,当程序执行event.wait()方法时就会阻塞,如果Flag值为True时,程序执行event.wait()方法时不会阻塞继续执行。
| 方法 | 描述 |
|---|---|
| wait() | 根据Flag的值判断是否要阻塞进程,Flag为True时阻塞,Flase时不阻塞 |
| set() | 将Flag的值改成True |
| clear() | 将Flag的值改成False |
| is_set() | 判断当前的Flag的值 |
举个栗子,假设我们要实现一个红绿灯运作程序,假设有30辆小车要通过红绿灯。
代码:
import time, random
from multiprocessing import Process, Event
def traffic_light(event):
"""红绿灯程序"""
while True:
if event.is_set(): # 判断事件中的Flag标记的值,如果是True,则亮红灯
print("红灯亮")
event.clear() # 亮完红灯以后,把Flag标记的值改为False
else:
print("绿灯亮")
event.set() # 亮完绿灯以后,把Flag标记的值改为True
time.sleep(2)
def car(i, event):
"""车"""
if not event.is_set():
print(f"car{i}等待红灯")
event.wait()
print(f"car{i}通过了路口。")
if __name__ == '__main__':
# 创建一个事件对象
event = Event()
p = Process(target=traffic_light, args=(event,))
p.start()
# 模拟30辆小车通过红绿灯
for i in range(30):
# 我们不知道什么时候有车来到路口,所以随机时间来模拟这个过程
time.sleep(random.randrange(0, 2))
p = Process(target=car, args=(i, event))
p.start()
池[重要]¶
生活中为了省力省电,家家户户都会在自家楼顶准备一个水池,方便用水。而我们现在所说的池(Pool),这个概念就是来自生活中的池子。在程序实际处理问题过程中,忙时会有成千上万的任务需要被执行,闲时可能只有零星几个任务。那么在成千上万个任务需要被执行的时候,我们就需要去创建成千上万个进程或线程么?首先,进程或线程的创建与结束是需要消耗时间的(即便线程的开销很小,但是蚊子再小也是肉呀)。其次,即便开启了成千上万的进程或线程,操作系统也不能让他们同时执行,这样反而会影响程序的效率。因此我们不能无限制的根据任务开启或者结束进程或线程。那么我们要怎么做呢?
对的,可以像生活中的水池一样,我们准备一个进程池或线程池,在里面放上固定数量的进程或线程,有任务来了,就拿池中的进程或线程对象来处理任务,等任务处理完毕,进程或线程并不关闭,而是将进程或线程再放回池中等待下一次任务到来。如果有很多任务需要并发执行,池中的进程或线程数量不够,任务就要等待之前的进程或线程执行任务完毕归来,拿到空闲进程或线程才能继续执行。也就是说,池中进程或线程的数量是固定的,那么同一时间最多有固定数量的进程或线程在运行。这样不仅减轻了操作系统的调度难度,还节省了开闭进程或线程的开销,同时实现了并发效果。
进程池(Process Pool)¶
要实现进程池,python中提供了2个模块提供操作:
- multiprocessing.Pool
- concurrent.futures.ProcessPoolExecutor
multiprocessing.Pool¶
multiprocessing.Pool创建的进程也提供2种不同的运行方式给我们:apply(同步调用),apply_async(异步调用)
同步调用进程池 (apply)¶
import time, os, random
from multiprocessing import Pool
def func(n):
print(f"子进程{n}执行了....")
time.sleep(2)
return f"子进程{n}"
if __name__ == '__main__':
start_time = time.time()
"""创建一个进程池"""
# n = os.cpu_count() # 本机CPU个数,我的是12,进程池容量个数自定义,默认CPU核数
# p = Pool(processes=n)
p = Pool(4) # 指定进程池中初始化时创建多少个进程在里面,默认根据操作系统的CPU逻辑数量来创建
"""往进程池里面的进程添加要执行的任务"""
res_list = []
# 创建20个任务
for i in range(20):
res = p.apply(func, args=(i,)) # 使用同步调用的方式,apply的返回值是任务的return返回值
res_list.append(res)
print(f'使用时间: {time.time() - start_time}')
print(f"全部任务的执行结果:{res_list}")
异步调用示例 (apply_async)¶
import time, os, random
from multiprocessing import Pool
def func(n):
print(f"子进程{n}执行了....")
time.sleep(2)
return f"子进程{n}"
if __name__ == '__main__':
start_time = time.time()
"""创建一个进程池"""
# n = os.cpu_count() # 本机CPU个数,我的是12,进程池容量个数自定义, 默认CPU逻辑核数
# p = Pool(processes=n)
p = Pool() # 指定进程池中初始化时创建多少个进程在里面,默认根据操作系统的CPU逻辑数量来创建
"""往进程池里面的进程添加要执行的任务"""
res_list = []
# 创建20个任务
for i in range(20):
res = p.apply_async(func, args=(i,)) # 使用异步调用的方式,apply_async的返回值是任务的异步结果对象
res_list.append(res) #
p.close() # 关闭进程池, 不再有新的任务加入到pool中, 防止进一步的操作
p.join() # 必须在close调用之后执行, 执行后等待所有子进程结束,否则报错
print(f'使用时间: {time.time() - start_time}')
results = [res.get() for res in res_list] # get() 同步阻塞方法
print(f"全部任务的执行结果:{results}")
进程池实现socketserver¶
server.py,代码:
import socket
from multiprocessing import Pool
def talk(conn):
"""通信方法"""
while True:
message = conn.recv(1024)
print(message)
conn.send(message)
conn.close()
if __name__ =="__main__":
sk = socket.socket()
sk.bind(("127.0.0.1", 9000))
sk.listen(5)
# Pool默认获取cpu_counter cpu最大逻辑核心数我的机器是12
p = Pool()
while True:
conn, addr = sk.accept()
p.apply_async(talk, args=(conn,))
sk.close()
client.py,代码:
import socket
sk = socket.socket()
sk.connect( ("127.0.0.1", 9000) )
while True:
content = input(">:")
sk.send(content.encode("utf-8"))
print(sk.recv(1024))
基于concurrent.futures实现进程池¶
pythnon3.4以后新增的
import random, time
from concurrent.futures import ProcessPoolExecutor
def func(n):
print(f"子进程{n}开始执行...")
time.sleep(random.randint(1, 3))
print(f"子进程{n}执行结束...")
return f"子进程{n}" # 任务的返回值
if __name__ == '__main__':
# 创建进程池,
# 可以通过processes参数指定进程池中初始化时创建多少个进程在里面,
# 默认根据操作系统的CPU逻辑数量来创建
p = ProcessPoolExecutor(max_workers=4)
res_list = []
for i in range(20):
res = p.submit(func, i) # 第一个参数为任务函数名,后续参数均为任务函数的参数
res_list.append(res) # submit的返回值是一个异步对象,通过对象的result方法可以获取任务结果
# print([res.result() for res in res_list]) # result阻塞同步方法,用于提取任务结果,也就是func的返回值
# 关闭进程池,后续不能继续执行submit提交任务,并阻塞等待所有的提交任务全部执行完成。
# 相当于原来的 for p in p_list: p.join()
p.shutdown()
print("主进程结束")
map方法¶
import random, time
from concurrent.futures import ProcessPoolExecutor
def func(n):
print(f"子进程{n}开始执行...")
time.sleep(random.randint(1, 3))
print(f"子进程{n}执行结束...")
return f"子进程{n}" # 任务的返回值
if __name__ == '__main__':
# 创建进程池,
# 可以通过processes参数指定进程池中初始化时创建多少个进程在里面,
# 默认根据操作系统的CPU逻辑数量来创建
p = ProcessPoolExecutor(max_workers=4)
# res_list = []
# for i in range(20):
# res = p.submit(func, i) # 第一个参数为任务函数名,后续参数均为任务函数的参数
# res_list.append(res) # submit的返回值是一个异步对象,通过对象的result方法可以获取任务结果
# print([res.result() for res in res_list]) # result阻塞同步方法,用于提取任务结果,也就是func的返回值
# 关闭进程池,后续不能继续执行submit提交任务,并阻塞等待所有的提交任务全部执行完成。
# 相当于原来的 for p in p_list: p.join()
# p.shutdown()
res_list = p.map(func, range(20))
print([res for res in res_list])
print("主进程结束")
adddonecallback方法¶
针对进程任务结果进行异步回调处理的。
import random, time
from concurrent.futures import ProcessPoolExecutor
def task(n):
print(f"子进程{n}开始执行...")
time.sleep(random.randint(1, 3))
print(f"子进程{n}执行结束...")
return f"子进程{n}" # 任务的返回值
def task_callback(res):
print(f"对任务结果进行异步回调处理:{res.result()}")
if __name__ == '__main__':
p = ProcessPoolExecutor(2)
for i in range(5):
p.submit(task, i).add_done_callback(task_callback)
p.shutdown()
print("主进程结束")
# 把结果处理流程编程了同步回调处理了
# res_list = []
# for i in range(5):
# res = p.submit(task, i)
# res_list.append(res)
#
# for res in res_list:
# task_callback(res) # result 同步阻塞
#
# p.shutdown()
# print("主进程结束")
线程池¶
threading模块并没有像multiprocessing模块那样提供类似进程池的功能,所以我们要实现线程池,只能通过concurrent.futures模块提供的ThreadPoolExecutor线程池类来实现,其用法与上面的的ProcessPoolExecutor一模一样。
import random
import time
from concurrent.futures import ThreadPoolExecutor
def func(n):
print(f"子线程{n}开始执行...")
time.sleep(random.randint(1, 5))
print(f"子线程{n}执行结束...")
return n
if __name__ == '__main__':
p = ThreadPoolExecutor(4)
results = []
for i in range(20):
res = p.submit(func, i) # 第一个参数为函数名,后续参数为函数的参数
results.append(res)
# p.shutdown() # 关闭进程池,后续不能继续执行submit提交任务,并阻塞等待所有的提交任务全部执行完成。
print([r.result() for r in results]) # 提取任务结果,也就是func的返回值
print("主线程结束")
# 这里也有maop方法,也有add_deno_callback的回调操作
线程池也有map方法,也有adddonecallback的结果异步回调操作。
综合案例:批量下载图片¶
爬虫:爬图片(漫画,图像素材),爬文本(小说,第三方接口信息),爬图文(商品信息,新闻)。
常见的图网:
乌云壁纸:https://www.obzhi.com/
彼岸图网:https://pic.netbian.com/
10壁纸:https://10wallpaper.com/
故宫壁纸:https://www.dpm.org.cn/lights/royal.html
壁纸工艺:https://wallpaperscraft.com/catalog/anime
致美化:https://zhutix.com/animated/
网络请求¶
TCP发送http网络请求¶
import socket
s = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
s.connect(('pic.netbian.com', 80))
s.send("""GET https://pic.netbian.com/ HTTP/1.1
Host: pic.netbian.com
""".encode())
content = b''
while True:
buf = s.recv(1024)
if buf == b'': break
content += buf
print(content.decode('gbk'))
上面基于TCP协议实现了http请求,但是这种原始的代码请求太麻烦了,而且不够严谨。所以python中有很多常用的http模块,可以帮我们实现http请求的发送与数据响应处理的。当然,我们后面学习到web阶段时,再讲。现在我们先使用一个最常用的requests模块来完成http请求操作。
基于requests发送http网络请求¶
安装requests模块
基本使用
import requests
"""
requests.get() 发送GET方法的http请求
requests.post() 发送POST方法的http请求
requests.put() 发送put方法的http请求
requests.patch() 发送patch方法的http请求
requests.delete() 发送delete方法的http请求
"""
"""获取bytes字节流内容"""
# 用于获取网络请求回来的二进制内容,例如:图片,软件,音频,压缩包等
# response = requests.get(url="https://pic.netbian.com/uploads/allimg/220523/002850-1653236930c7b6.jpg")
# with open("images/1.png", "wb") as f:
# f.write(response.content)
"""获取文本内容"""
# 用于获取网络请求回来的文本格式内容,例如:web网站的html网页,企业设备的txt文本,分布式项目的日志文件,json等
response = requests.get(url="https://pic.netbian.com/")
# print(response.content.decode("gbk")) # 如果要获取非utf-8编码的文本内容
print(response.text) # 用于获取utf-8编码格式的文本内容
同步实现¶
"""
1. 使用正则分析并提取总页数一共有多少,在页面中的什么位置。
<div class="page">
<a href="/4kdongman/index_3.html">上一页</a>
<a href="/4kdongman/index.html">1</a>
<span class="slh">…</span>
<a href="/4kdongman/index_2.html">2</a>
<a href="/4kdongman/index_3.html">3</a>
<b>4</b>
<a href="/4kdongman/index_5.html">5</a>
<a href="/4kdongman/index_6.html">6</a>
<a href="/4kdongman/index_7.html">7</a>
<a href="/4kdongman/index_8.html">8</a>
<a href="/4kdongman/index_9.html">9</a>
<span class="slh">…</span>
<a href="/4kdongman/index_117.html">117</a>
<a href="/4kdongman/index_5.html">下一页</a>
<span class="text">共117页 到第</span><input type="text" name="page"><span>页</span>
<a href="javascript:;" id="jump-url">确定</a>
</div>
2. 分析每一页列表页内容的url地址特点:
第1页:https://pic.netbian.com/4kdongman/index.html
第2页:https://pic.netbian.com/4kdongman/index_2.html
第3页:https://pic.netbian.com/4kdongman/index_3.html
第4页:https://pic.netbian.com/4kdongman/index_4.html
...
第n页:https://pic.netbian.com/4kdongman/index_n.html
3. 分析我们要下载(爬取)的内容在列表页中的什么位置?链接在哪里?
<div class="slist">
<ul class="clearfix">
<li><a href="/tupian/28992.html" target="_blank"><img src="/uploads/allimg/220225/221617-16457985774f37.jpg" alt="原神和煦希望之风4k壁纸"><b>原神和煦希望之风4k壁纸</b></a></li>
<li><a href="/tupian/28790.html" target="_blank"><img src="/uploads/allimg/220204/182036-16439700367bad.jpg" alt="原神云堇4k电脑壁纸3840x2160"><b>原神云堇4k电脑壁纸3840</b></a></li>
....
<li><a href="/tupian/28906.html" target="_blank"><img src="/uploads/allimg/220215/234715-1644940035c237.jpg" alt="敦煌飞天 女孩 佛像 3d美女3440x1440带鱼屏壁纸"><b>敦煌飞天 女孩 佛像 3d美</b></a></li>
<li class="nextpage"><a href="/4kdongman/index_5.html"><p>下一页<br>更多精彩</p></a></li>
</ul>
</div>
4. 当我们打开内容所在的url地址,真正的内容在页面中的什么位置?
<a href="" id="img"><img src="/uploads/allimg/220215/234715-1644940035827c.jpg" data-pic="/uploads/allimg/220215/234715-1644940035c237.jpg" alt="敦煌飞天 女孩 佛像 3d美女3440x1440带鱼屏壁纸" title="敦煌飞天 女孩 佛像 3d美女3440x1440带鱼屏壁纸"></a>
"""
import re
import os
import requests
base_url = "https://pic.netbian.com"
# 获取主页面内容
main_page = requests.get(base_url+"/4kdongman").text.encode('iso-8859-1').decode('gbk')
# print(main_page)
# 从主页面内容中获取总页数
total_page = re.findall(r'<div class="page">.*">(\d+).*</a><a .*?下一页</a></div>', main_page, re.M | re.S)
if total_page:
total_page = int(total_page[0])
# 生成列表页的连接地址
list_page_url = []
for i in range(1, total_page+1):
if i == 1:
url = f"https://pic.netbian.com/4kdongman/index.html"
else:
url = f"https://pic.netbian.com/4kdongman/index_{i}.html"
list_page_url.append(url)
for url in list_page_url:
list_page = requests.get(url).text.encode('iso-8859-1').decode('gbk')
# print(list_page)
content = re.findall(r'<div class="slist">.*?</ul>', list_page, re.M | re.S)
content_info_list = re.findall(r'<li>.*?href="(.*?)".*?</a></li>', content[0], re.M | re.S)
for content_info in content_info_list:
content_url = f"{base_url}{content_info}"
content_page = requests.get(content_url).text.encode('iso-8859-1').decode('gbk')
content_info = re.findall(r'id="img"><img src="(.*?)".*?title="(.*?)"></a>', content_page, re.M | re.S)
image = requests.get(base_url+content_info[0][0]).content
with open(f"images/{os.path.basename(content_info[0][0])}", "wb") as f:
f.write(image)
封装代码,代码:
import re
import os
import requests
base_url = "https://pic.netbian.com"
# 发送http网络请求
def get_page(url, type="text"):
try:
reponse = requests.get(url)
except:
raise Exception("网络请求错误!请检查网络或请求URL地址是否有误!")
if type == "text":
content = reponse.text
try:
content = content.encode('iso-8859-1').decode('gbk')
except:
content = content.encode('utf-8').decode('utf-8')
else:
content = reponse.content
return content
def re_findall(pattern, content):
return re.findall(pattern, content, re.M | re.S)
def get_total_page(page):
total_page = re_findall(r'<div class="page">.*">(\d+).*</a><a .*?下一页</a></div>', page)
if total_page:
total_page = int(total_page[0])
else:
total_page = 0
return total_page
def get_list_url(total_page):
list_page_url = []
for i in range(1, total_page + 1):
if i == 1:
url = f"https://pic.netbian.com/4kdongman/index.html"
else:
url = f"https://pic.netbian.com/4kdongman/index_{i}.html"
list_page_url.append(url)
return list_page_url
def request_content_page(content_info):
content_url = f"{base_url}{content_info}"
content_page = get_page(content_url)
content_info = re_findall(r'id="img"><img src="(.*?)".*?title="(.*?)"></a>', content_page)
image = get_page(base_url + content_info[0][0], "")
with open(f"images/{os.path.basename(content_info[0][0])}", "wb") as f:
f.write(image)
def get_list_page(url):
list_page = get_page(url)
content = re_findall(r'<div class="slist">.*?</ul>', list_page)
content_info_list = re_findall(r'<li>.*?href="(.*?)".*?</a></li>', content[0])
return content_info_list
if __name__ == '__main__':
# 获取主页面内容
main_page = get_page(base_url+"/4kdongman")
# 从主页面内容中获取总页数
total_page = get_total_page(main_page)
# 生成列表页的连接地址
list_page_url = get_list_url(total_page)
# 从处理每一个列表页信息
for url in list_page_url:
content_info_list = get_list_page(url)
for content_info in content_info_list:
request_content_page(content_info)
异步实现¶
可以采用多进程或多线程来实现。甚至后面学习的协程也可以实现异步爬虫效果。这里我们基于之前所学的进程池或线程池来完成这个操作。
from concurrent.futures import ProcessPoolExecutor
import re
import os
import requests
base_url = "https://pic.netbian.com"
# 发送http网络请求
def get_page(url, type="text"):
try:
reponse = requests.get(url)
except:
raise Exception("网络请求错误!请检查网络或请求URL地址是否有误!")
if type == "text":
content = reponse.text
try:
content = content.encode('iso-8859-1').decode('gbk')
except:
content = content.encode('utf-8').decode('utf-8')
else:
content = reponse.content
return content
def re_findall(pattern, content):
return re.findall(pattern, content, re.M | re.S)
def get_total_page(page):
total_page = re_findall(r'<div class="page">.*">(\d+).*</a><a .*?下一页</a></div>', page)
if total_page:
total_page = int(total_page[0])
else:
total_page = 0
return total_page
def get_list_url(total_page):
list_page_url = []
for i in range(1, total_page + 1):
if i == 1:
url = f"https://pic.netbian.com/4kdongman/index.html"
else:
url = f"https://pic.netbian.com/4kdongman/index_{i}.html"
list_page_url.append(url)
return list_page_url
def request_content_page(content_info):
content_url = f"{base_url}{content_info}"
content_page = get_page(content_url)
content_info = re_findall(r'id="img"><img src="(.*?)".*?title="(.*?)"></a>', content_page)
image = get_page(base_url + content_info[0][0], "")
with open(f"images/{os.path.basename(content_info[0][0])}", "wb") as f:
f.write(image)
def get_list_page(url):
list_page = get_page(url)
content = re_findall(r'<div class="slist">.*?</ul>', list_page)
content_info_list = re_findall(r'<li>.*?href="(.*?)".*?</a></li>', content[0])
return content_info_list
if __name__ == '__main__':
# 获取主页面内容
main_page = get_page(base_url+"/4kdongman")
# 从主页面内容中获取总页数
total_page = get_total_page(main_page)
# 生成列表页的连接地址
list_page_url = get_list_url(total_page)
pool = ProcessPoolExecutor()
# 从处理每一个列表页信息
for url in list_page_url:
pool.submit(get_list_page, url).add_done_callback(request_content_page)
pool.shutdown()
协程¶
基本概念¶
协程(Coroutine),是一种用户态的轻量级线程,又称微线程,纤程,可以实现单线程下的并发。是一种用户态内进行上下文切换的技术,由用户程序自己控制任务调度的,简而言之,其实就是通过线程可以实现代码块相互切换执行。协程与线程、进程同属于python中实现异步多任务的常用方式。
那么,为什么有了线程以后,还要有协程呢?
首先作为开发人员,我们追求肯定是提高系统资源的利用率。从单进程到多进程提高了 CPU 利用率;从进程到线程,降低了上下文切换的开销;而从线程到协程,其实就是为了进一步降低了上下文切换的开销,使得高并发的服务可以使用简单的代码写出来的。
那如何实现一个协程呢?
在Python中有2种方式可以实现协程:
- python原生语法实现:生成器(yield & yield from) ----> async & await ---> asyncio(底层)
- C语言底层模块显示:greenlet ----> gevent / eventlet
同步代码:
def func1():
print("1-1. func1任务执行了")
# ....
print("1-2. func1任务结束了")
def func2():
print("2-1. func1任务执行了")
# ....
print("2-2. func1任务结束了")
if __name__ == '__main__':
func1()
func2()
基于之前的学习,我们可以使用多进程或多线程,来实现多任务的上下文切换,但是此处我们使用协程来实现多任务切换。
基于生成器实现协程¶
# 在普通函数中使用了yield关键字以后,该函数就会变成生成器函数
def func1():
print("1-1. func1任务执行了")
yield from func2() # 交出CPU的执行权,去迭代执行 func2生成器函数(CPU资源的让渡),
print("1-2. func1任务结束了")
def func2():
print("2-1. func1任务执行了")
yield # 也进行了交出CPU的执行权(让渡)
print("2-2. func1任务结束了")
if __name__ == '__main__':
# print(func1()) # 生成器函数的返回值是一个生成器对象
for item in func1():
item
# 实现了一个线程内多个任务交替执行,这就是协程 !!!
注意:单个线程内可以运行任意个数量协程,不同线程之间不能切换协程的,而且协程本质上就是就是开发人员自己实现的多任务调度,所以对于CPU来说,多少个协程都是同一个线程。换句话说,就是CPU能识别的最小任务调度单位是线程,而对于协程来说,CPU是不识别的或不可见。
greenlet模块实现协程¶
Greenlet是python的一个使用C语言底层实现的第三方模块,主要作用实现协程。与生成器不同的是,greenlet是通过switch方法来实现多任务切换。
安装
基本使用
from greenlet import greenlet
def func1():
print("1-1. func1任务执行了") # 第2步:输出 1-1
g2.switch(2) # 第3步:调度切换,调度执行func2,并把参数2传递到任务中
print("1-2. func1任务结束了") # 第7步:输出 1-2
def func2(n):
print(f"{n}-1. func1任务执行了") # 第4步,输出n-1
print(f"{n}-2. func1任务结束了") # 第5步,输出n-2
g1.switch() # 第6步,调度切换,调度执行func1,恢复func1的执行状态
if __name__ == '__main__':
# 创建2个协程,参数就是协程要执行的任务
g1 = greenlet(func1)
g2 = greenlet(func2)
g1.switch() # 第1步,切换协程,并且也可以传递参数到协程任务中
print("主程序") # 第8步,因为不再有协程需要执行了,所以主程序结束
Python的线程属于内核级别的,即由操作系统进行系统调度来控制的,如果单线程遇到IO或执行时间过长就会被迫交出cpu执行权限,切换其他线程运行。而使用协程一旦遇到IO阻塞,就需要在代码中手动控制切换(而非操作系统,让渡),以此来提升效率。所以协程的使用看个人的编程能力,用得好,程序执行效率就高,用的差的,反而影响了程序的执行效率。
那么,我们应该在什么时候编写代码让协程让渡CPU的执行权呢?就是代码遇到IO阻塞的时候让渡。
所以,我们怎么识别或检测到任务代码中的IO阻塞并自动切换调度到其他任务呢?
gevent模块实现协程调度¶
gevent是一个第三方库。通过gevent模块提供的操作,我们可以轻松实现并发同步或异步编程,gevent模块是在greenlet模块基础上实现协程并实现了自动检测IO阻塞就会切换任务的功能。
安装
常用属性或方法¶
| 常用属性/方法 | 描述 |
|---|---|
| gevent.spawn(*args, **kwargs) | 创建greenlet协程对象,第一个参数是协程要执行的任务函数或方法 |
| gevent.sleep(seconds) | 异步阻塞指定秒数 |
| greenlet.join() | 异步阻塞等待某个协程执行完毕,greenlet为协程对象 |
| gevent.joinall(greenlets) | 异步阻塞等待所有的协程列表greenlets都执行完毕 |
| greenlet.value | 获取协程任务的返回结果,greenlet为协程对象 |
| greenlet.link_value(callback) | 注册协程任务的异步结果处理函数,greenlet为协程对象 |
基本使用¶
代码:
import time
import gevent
def func():
# 获取当前协程对象
print("协程运行了!")
if __name__ == '__main__':
# 创建Greenlet协程对象
g1 = gevent.spawn(func)
# 阻塞3秒
gevent.sleep(3)
# 相当于time.sleep(1),但是time.sleep无法被协程识别,
# 因为协程只能识别属于的异步的阻塞,而time.sleep属于一种同步的阻塞,所以无法切换调度到其他任务
多任务遇到IO阻塞自动切换协程¶
代码:
import gevent
def func1():
print("1-1. func1任务执行了")
gevent.sleep(2)
print("1-2. func1任务结束了")
def func2():
print("2-1. func1任务执行了")
gevent.sleep(2)
print("2-2. func1任务结束了")
if __name__ == '__main__':
g1 = gevent.spawn(func1)
g2 = gevent.spawn(func2)
g1.join()
g2.join()
gevent实现遇到IO阻塞自动切换任务的内部原理,以上面代码为例:
gevent内部实现了libev事件循环(可以简单为死循环,),
我们调用gevent的spawn创建greenlet协程对象就是添加了一个协程对象到事件循环内部,类似如下:
while True:
greenlet.func1()
greenlet.func2()
当程序代码运行时,也就是循环过程中遇到了gevent.sleep(3), 实际上,就是记录了当前调用gevent.sleep(3)的当前时间戳和阻塞等待时间戳而已。
假设在主程序中,先调用gevent.sleep(3),实际上就是在协程内部,使用time.time(),记录了当前时间戳(假设是x秒,),
还根据当前时间戳+阻塞的时间(此处假设3秒)得到阻塞等待时间戳,
那么当前线程中就会有一个列表(调度时间表):[(协程ID,x, x+3)],
接着就去切换到事件循环中下一个协程func1,如果协程有gevent.sleep(2),则进行再次使用time.time()记录当前时间戳,并记录x+2,
那么当前线程中的调度时间表变成:[(协程ID,x, x+3), (协程ID, x, x+2), ],
接着往下调度到另一个任务func2,执行func2的协程中如果再次遇到gevent.sleep(1),那么会再次使用time.time()记录当前时间戳,并记录x+1,
那么当前线程中的调度时间表变成:[(x+3, x, 协程ID为), (x+2,x, 协程func1), (x+1,x, 协程func2ID), ],
如果当前线程没有其他的协程了,那么调度时间表中使用min函数取出最小时间戳对应信息出来
min([(x+3, x, 协程ID为), (x+2,x, 协程func1), (x+1,x, 协程func2ID), ]),提取到(x+1, x, 协程func2)
判断时间是否到了,没到就阻塞等待,到了就直接执行对应的该时间戳的协程对应的代码func2
执行func2协程的过程中,如果没有再次遇到gevent.sleep的话,则协程直接执行结束,
主程序会再次从调度时间表使用min函数取出最小时间戳对应信息出来
min([(x+3, x, 协程ID为), (x+2,x, 协程func1)]),提取到(x+2, x, 协程func1)
再次等待1秒,时间到,执行对应的func1协程,协程执行如果没有再次遇到阻塞,
则再次从调度时间表使用min取出最小时间戳对应信息出来
min([(x+3, x, 协程ID为)]),提取到(x+3, x, 协程func1)
再次等待1秒,事件到,执行主程序了。
joinall方法¶
joinall基于libev事件循环实现多个协程阻塞等待执行结束。
import time
import gevent
def func1():
print("1-1. func1任务执行了")
gevent.sleep(2)
print("1-2. func1任务结束了")
def func2():
print("2-1. func1任务执行了")
gevent.sleep(2)
print("2-2. func1任务结束了")
if __name__ == '__main__':
task_list = [
gevent.spawn(func1),
gevent.spawn(func2)
]
# g1.join()
# g2.join()
gevent.joinall(task_list)
value获取任务结果¶
单个任务结果获取
import time
import gevent
def func():
print("1-1. func1任务执行了")
time.sleep(2)
print("1-2. func1任务结束了")
return "func1"
if __name__ == '__main__':
g = gevent.spawn(func)
print(g.value) # None,没有获取到结果
# value是一个存储协程任务结果的一个属性,并非函数,所以不会阻塞等待结果,
# 因此我们要提取任务结果,必须在协程执行以后来获取,所以需要卸载join之后。
g.join()
print(g.value)
多个任务结果获取
import random
import time
import gevent
def func(n):
print(f"{n}-1. func{n}任务执行了")
gevent.sleep(random.randint(1,3))
print(f"{n}-2. func{n}任务结束了")
return f"func{n}的结果"
if __name__ == '__main__':
task_list = []
for i in range(10):
task_list.append(gevent.spawn(func, i))
# 这里代码有问题的,因为只有所有的异步任务都结束了以后,才会进入for循环
gevent.joinall(task_list)
# 也就意味着,如果不是所有任务都执行结束以后,for是不会输出结果。
# 所以这种获取结果的方式有局限
# 因此,我们要是希望,异步任务执行过程中,单个任务执行结束以后,能先对该任务的结果进行处理的话,怎么做呢?
for task in task_list:
print(task.value)
协程任务异步回调处理
可以基于greenlet协程对象提供的rawlink给当前协程任务注册回调函数即可。代码:
import random
import time
import gevent
def func(n):
print(f"{n}-1. func{n}任务执行了")
gevent.sleep(random.random())
print(f"{n}-2. func{n}任务结束了")
return f"func{n}的结果"
def callback(g):
"""
协程任务的回调处理
:param g: 当前协程对象
:return:
"""
print(g.value)
if __name__ == '__main__':
task_list = []
for i in range(10):
# g greenlet协程对象
g = gevent.spawn(func, i)
# 给协程对象注册结果回调处理函数
g.link_value(callback)
# g.rawlink(callback)
task_list.append(g)
gevent.joinall(task_list)
猴子补丁[了解]¶
猴子补丁的这个叫法起源于Python的一个著名的重量级web框架-Zope,大家在修正Zope的Bug时经常在程序后面追加更新部分代码,这些被称作是 “杂牌军补丁(guerilla-patch)”,后来guerilla就渐渐的写成了 gorilla(大猩猩),再后来就写了monkey(猴子),所以猴子补丁的叫法是这么莫名其妙的得来的。 后来在很多的动态语言中,不改变源代码而对功能进行追加和变更的作用,都统称为“猴子补丁(monkey-patch)”。所以猴子补丁并不是Python中专有的。说白了,猴子补丁就是在模块运行的时候替换或重写模块中的某些方法或函数。
import time
import gevent
print(time.sleep) # <built-in function sleep>
# 在导包以后,在程序执行之前,给所有的会导致线程阻塞的方法或函数进行重写
from gevent import monkey
monkey.patch_all()
print(time.sleep) # <function sleep at 0x000001E561584B80>
def func():
# 获取当前协程对象
print("协程func开始运行了!")
time.sleep(3)
print("协程func运行结束了!")
if __name__ == '__main__':
# 创建Greenlet协程对象
g1 = gevent.spawn(func)
# time.sleep(1) # 如果使用time则会导致当前阻塞会线程接管,而协程无法识别,也无法干扰
# python里面除了time.sleep以外,还有很多会导致线程阻塞的函数或方法,这些函数与方法都无法被协程识别或干扰
# 所以,我们需要使用由gevent提供的猴子补丁(monkey-patch)来对python常见的一些导致线程阻塞的函数或方法进行替换
time.sleep(3)
通过gevent实现单线程下的socketServer¶
server.py,代码:
import gevent
import socket
# 打个猴子补丁
from gevent import monkey
monkey.patch_all()
sk = socket.socket()
sk.bind(('127.0.0.1', 9000))
sk.listen(5)
def chat(conn, addr):
try:
while True:
res = conn.recv(1024).decode("utf-8")
if res == "": break
print(f'客户端[{addr}]: {res}')
conn.send(res.upper().encode("utf-8")) # send 与上面 recv 都是猴子补丁重写后的方法了。
except Exception as e:
print(e)
finally:
conn.close()
while True:
conn, addr = sk.accept()
print(f'客户端[{addr}]成功连接到服务端!')
gevent.spawn(chat, conn, addr)
client.py,代码:
from socket import *
sk = socket()
sk.connect(('127.0.0.1', 9000))
while True:
msg = input('>: ').strip()
if not msg: continue
sk.send(msg.encode('utf-8'))
msg = sk.recv(1024)
print(msg.decode('utf-8'))
通过上面的例子,我们可以再次看到协程可以通过单线程内在多个上下文中进行来回切换执行,也可以看到协程在IO密集型操作中,可以利用在IO等待时间就去切换执行其他任务,当IO操作结束后再自动回调,那么就会大大节省资源并提升性能,从而实现异步编程也就是不等待任务结束就可以去执行其他代码。当然,也要注意的是,协程在计算密集型操作中,如果利用协程来回频繁切换执行,实际上是没有任何意义,因为来回切换并保存代码执行状态反倒会导致程序降低性能。
因此对比操作系统控制线程的上下文切换,用户在单线程内控制协程的上下文切换会带来以下的优缺点和特点:
优点:
- 无须像线程一样通过系统调度来进行上下文切换,较少了系统开销;
- 无须锁定及同步的操作,所以不需要加锁了。
- 主动切换代码的执行流程,简化编程的模型;
- 与进程、线程一样可以达到高并发性、高扩展性,而且比进程、线程要成本更低。
缺点:
- 无法利用多核,因为协程的本质是单线程下工作,当然我们可以通过一个程序开启多个进程,每个进程内开启多个线程,每个线程内开启多个协程来解决这个问题。
- 协程无法被操作系统感知,对于操作系统而言就是单个线程内部代码,因而一旦协程出现阻塞,将会阻塞整个线程,所以我们针对系统能感知的一些阻塞的代码使用猴子补丁进行规避。
特点:
- 在只有一个单线程里就通过代码实现并发
- 修改共享数据不需加锁,协程不会出现同时对共享数据进行同时需改的情况。
- 用户程序里自己可以保存多个控制流的上下文栈(greelet与生成器帮我们实现协程的控制块)
- 协程遇到IO操作自动切换到其它协程(如何实现检测IO?yield、greenlet都无法实现,就用到了gevent模块或者asyncio模块来实现[它们怎么自动检车IO并实现上下文的切换,利用的IO多路复用的技术来实现的。IO多路复用,我们后面学习,现在只要知道gevent实际上本质就是IO多路复用技术里面select模型])
协程池[了解]¶
代码:
import gevent
from gevent import pool
def func1():
print("1-1, func1开始执行了")
gevent.sleep(2)
print("1-2, func1执行结束了")
def func2():
print("2-1,func2开始执行了")
gevent.sleep(2)
print("2-2,func2执行结束了")
if __name__ == '__main__':
# 协程池
p = pool.Pool()
p.apply_async(func1)
p.apply_async(func2)
p.join()
asyncio 模块实现协程调度¶
python3.4之前使用的都是gevent、eventlet、ternardo、twisted实现协程操作。
在Python3.4之前官方未提供协程的类库,一般大家都是使用greenlet等其他来实现。在Python3.4发布后官方正式支持协程,即:asyncio模块,不需要单独安装。
asyncio的编程模型就是一个事件循环。我们可以从asyncio模块中直接获取一个EventLoop事件循环的引用对象,然后把需要执行的协程任务注册到EventLoop事件循环中执行,就实现了异步协程了。
事件循环¶
事件循环,可以把他当做是一个while循环,这个while循环在周期性的运行并执行一些任务,在特定条件下终止循环。
# 伪代码
任务列表 = [ 任务1, 任务2, 任务3,... ]
while True:
可执行的任务列表,已完成的任务列表 = 去任务列表中检查所有的任务,将'可执行'和'已完成'的任务返回
for 就绪任务 in 已准备就绪的任务列表:
执行已就绪的任务
for 已完成的任务 in 已完成的任务列表:
在任务列表中移除 已完成的任务
如果 任务列表 中的任务都已完成,则终止循环
可以asyncio通过如下代码来获取和创建事件循环。
import asyncio
if __name__ == '__main__':
loop = asyncio.get_event_loop()
print(loop)
# <ProactorEventLoop running=False closed=False debug=False>
# 本质上就是一个在主线程不断运行的while循环
基本使用¶
import asyncio
@asyncio.coroutine
def func1():
print("1-1. func1任务执行了")
yield from asyncio.sleep(2) # 遇到IO耗时操作,自动化切换到tasks中的其他任务
print("1-2. func1任务结束了")
if __name__ == '__main__':
"""方式1:Python 3.7以前"""
# 1. 创建一个事件循环
# loop = asyncio.get_event_loop()
# 2. 基于loop提供的run_until_complete就可以注册生成器对象到事件循环中,自动运行
# loop.run_until_complete(func1())
"""方式2:Python 3.7以后"""
# 本质上方式一是一样的,内部先 创建事件循环 然后执行 run_until_complete,一个简便的写法。
# asyncio.run 函数在 Python 3.7 中加入 asyncio 模块,
asyncio.run(func1())
async & await¶
async 与 await 关键字是Python3.5版本中新增的关键字,基于生成器实现协程的一个快捷语法,让代码可以更加简便。Python3.8之后 @asyncio.coroutine 装饰器就会被废弃,官方推荐使用async & awiat 关键字实现协程异步编程。
await是一个只能在协程函数(使用 async 关键字标记的函数)中使用的关键字,用于遇到IO操作时挂起当前协程(任务),当前协程(任务)挂起过程中事件循环就可以自动切换去执行其他的协程(任务),当前协程IO处理挂起状态结束以后,会自动再次切换回来执行await之后的代码。
基本语法
# 定义一个协程函数,在声明普通函数的左边,增加关键字async,就表示当前函数就是一个异步函数(协程)
async def func():
pass
# 调用协程函数,函数内部代码不会执行,返回一个协程对象
result = func()
async与await需要配合官方提供的asyncio模块进行使用的,代码:
import asyncio
async def func():
print("执行协程函数内部代码")
# 遇到IO操作挂起当前协程(任务),等IO操作完成之后再继续往下执行。
# 当前协程挂起时,事件循环可以去执行其他协程(任务)。
response = await asyncio.sleep(2)
print("IO请求结束,结果为:", response)
if __name__ == '__main__':
result = func()
asyncio.run(result)
代码:
import asyncio
async def func1():
print("协程函数func1开始执行了")
await asyncio.sleep(2)
return "func1的执行结果"
async def func2():
print("协程函数func2开始执行了")
# 遇到IO操作挂起当前协程(任务),等IO操作完成之后再继续往下执行。
# 当前协程挂起时,事件循环可以去执行其他协程(任务)。
response = await func1()
print("IO请求结束,结果为:", response)
if __name__ == '__main__':
# 不能直接调用异步函数,需要使用asyncio模块来运行,否则警告
print(func2()) # <coroutine object func2 at 0x00000172CC3B11C0>
asyncio.run(func2())
asyncio提供的常用方法¶
| 方法 | 描述 |
|---|---|
await asyncio.sleep(delay, result) |
异步阻塞指定之间,delay参数的值为异步阻塞时间,result的值为阻塞时间结束以后的返回结果 |
| asyncio.geteventloop() | 获得一个事件循环实例对象。 |
await asyncio.wait(fs) |
并发地运行 fs 可迭代对象中的 可等待对象 并进入阻塞状态 |
| asyncio.ensure_future(coro) | 创建Task异步任务对象,coro为异步函数 |
| loop.rununtilcomplete(future) | 阻塞运行一个或多个异步任务future,future是异步函数返回的可等待对象 |
| asyncio.create_task(coro) | 创建Task异步任务对象,coro为异步函数 |
| asyncio.run(main) | 创建事件循环,运行一个协程,协程执行结束以后关闭事件循环。 |
| asyncio.as_completed(fs) | 从执行结束的异步任务队列中返回异步任务结果的迭代器 |
| task.result() | 获取异步任务的返回结果,task为Task异步任务对象 |
| task.adddonecallback(fn) | 设置异步任务的返回结果的异步回调函数,fn为函数名 |
多协程调度¶
在程序想要创建多个任务对象,可以使用asyncio模块提供的Task对象来实现。Task可以用于并发调度协程,通过asyncio.create_task(协程对象)的方式创建Task对象,这样可以让协程加入事件循环中等待被调度执行。除了使用 asyncio.create_task() 函数以外,还可以用低层级的 loop.create_task() 或 ensure_future() 函数。
python3.7以前的多任务调度,代码:
import asyncio
async def func1():
print("1-1. func1任务执行了")
await asyncio.sleep(2) # 遇到IO耗时操作,自动化切换到tasks中的其他任务
print("1-2. func1任务结束了")
async def func2():
print("2-1. func2任务执行了")
await asyncio.sleep(2) # 遇到IO耗时操作,自动化切换到tasks中的其他任务
print("2-2. func2任务结束了")
if __name__ == '__main__':
# python3.7以前的asyncio是沒有run方法的,就要自己手动获取事件循环对象
# 注意:此处并非创建一个事件循环对象,这个事件循环对象在python中内部已经创建了
loop = asyncio.get_event_loop()
# # 注册协程对象,返回task异步任务对象
# task1 = asyncio.ensure_future(func1())
# task2 = asyncio.ensure_future(func2())
#
# # 把task对象添加到协程的就绪(等待)列表
# task_list = asyncio.wait([task1,task2])
#
# # 把就需要列表中的所有task异步任务对象添加到事件循环中执行
# loop.run_until_complete(task_list)
"""简写操作"""
task_list = asyncio.wait([
asyncio.ensure_future(func1()),
asyncio.ensure_future(func2())
])
loop.run_until_complete(task_list)
python3.7以后的多任务调度,代码:
import asyncio
async def func1():
print("1-1. func1任务执行了")
await asyncio.sleep(2) # 遇到IO耗时操作,自动化切换到tasks中的其他任务
print("1-2. func1任务结束了")
async def func2():
print("2-1. func2任务执行了")
await asyncio.sleep(2) # 遇到IO耗时操作,自动化切换到tasks中的其他任务
print("2-2. func2任务结束了")
async def main():
print("main子协程开始执行")
task_list = [
# 创建协程,将协程封装到一个Task对象中。
asyncio.create_task(func1(), name="f1"),
asyncio.create_task(func2(), name="f2"),
]
# 添加到事件循环的任务列表中,等待事件循环去执行(默认是就绪状态)
await asyncio.wait(task_list)
print("main子协程执行结束")
if __name__ == '__main__':
asyncio.run(main())
获取任务返回结果¶
python3.7以前写法,代码:
import asyncio
async def func():
print("func任务执行了!")
await asyncio.sleep(2)
print("func任务结束了!")
return 'func的执行结果'
if __name__ == '__main__':
loop = asyncio.get_event_loop()
task = loop.create_task(func())
loop.run_until_complete(task)
ret = task.result()
print(f"函数的返回结果:{ret}")
python3.7以后的写法,代码:
import asyncio
async def func():
print("func任务执行了!")
await asyncio.sleep(2)
print("func任务结束了!")
return 'func'
if __name__ == '__main__':
task = asyncio.run(func())
print(f"函数的返回结果:{task}")
python3.7还可以简写代码,代码:
import asyncio
async def func():
print("func任务执行了!")
await asyncio.sleep(2)
print("func任务结束了!")
return 'func'
async def main():
print("main开始")
task = asyncio.create_task(func())
print("main结束")
# 当执行某协程遇到IO操作时,会自动化切换执行其他任务。
# 此处的await是等待相对应的协程全都执行完毕并获取结果
ret1 = await task
print(f"此处获取的ret1就是异步返回结果,ret1={ret1}")
if __name__ == '__main__':
asyncio.run(main())
多协程的任务结果¶
python3.7以前的写法,代码:
import asyncio
async def func1():
print("1-1. func1任务执行了")
await asyncio.sleep(2) # 遇到IO耗时操作,自动化切换到tasks中的其他任务
print("1-2. func1任务结束了")
return "func1"
async def func2():
print("2-1. func1任务执行了")
await asyncio.sleep(2) # 遇到IO耗时操作,自动化切换到tasks中的其他任务
print("2-2. func1任务结束了")
return "func2"
if __name__ == '__main__':
loop = asyncio.get_event_loop()
task_list = [
loop.create_task(func1()),
loop.create_task(func2()),
]
wait_tasks = asyncio.wait(task_list)
loop.run_until_complete(wait_tasks)
for task in task_list:
print(task.result())
python3.7以后的写法,代码:
import asyncio
async def func1():
print("1-1. func1任务执行了")
await asyncio.sleep(2) # 遇到IO耗时操作,自动化切换到tasks中的其他任务
print("1-2. func1任务结束了")
return "func1"
async def func2():
print("2-1. func1任务执行了")
await asyncio.sleep(2) # 遇到IO耗时操作,自动化切换到tasks中的其他任务
print("2-2. func1任务结束了")
return "func2"
async def main():
task_list = [
asyncio.create_task(func1()),
asyncio.create_task(func2()),
]
await asyncio.wait(task_list)
for task in task_list:
ret = await task
print(f"异步任务的返回结果:{ret}")
if __name__ == '__main__':
asyncio.run(main())
上面代码获取的结果是同步方式来获取结果的,如果希望实现哪个协程先执行完,就对哪个协程结果先进行处理,我们还需要修改下代码。
多任务结果异步获取¶
python3.7以前写法,代码:
import random
import asyncio
async def func(i):
print(f"异步任务func{i}任务执行了")
t = random.randint(1, 10)
await asyncio.sleep(t) # 遇到IO耗时操作,自动化切换到tasks中的其他任务
print(f"异步任务func{i}任务结束了")
return f"func{i}执行结果,耗时:{t}秒" # 此处的返回值,最终在python底层会被分装一个可等待对象
async def main():
task_list = []
# 注冊创建10个协程
for i in range(10):
task = asyncio.ensure_future(func(i))
task_list.append(task)
for res in asyncio.as_completed(task_list): # 从执行结束的任务队列中提取任务对象
print(res) # 等待对象,实际上是asyncio.Future,叫可等待对象,可等待对象就可以使用await关键字提取结构
result = await res # 因此await后面必须是asyncio封装的可等待对象
print(result)
if __name__ == '__main__':
loop = asyncio.get_event_loop()
loop.run_until_complete(main())
python3.7以前的另一种写法,代码:
import random
import asyncio
async def func(i):
print(f"异步任务func{i}任务执行了")
t = random.randint(1, 10)
await asyncio.sleep(t) # 遇到IO耗时操作,自动化切换到tasks中的其他任务
print(f"异步任务func{i}任务结束了")
return f"func{i}执行结果,耗时:{t}秒" # 此处的返回值,最终在python底层会被分装一个可等待对象
def callback(res):
print(res.result())
async def main():
task_list = []
# 注冊创建10个协程
for i in range(10):
task = asyncio.ensure_future(func(i))
task.add_done_callback(callback)
task_list.append(task)
await asyncio.wait(task_list)
if __name__ == '__main__':
loop = asyncio.get_event_loop()
loop.run_until_complete(main())
python3.7以后的写法实际上就是上面的adddonecallback写法,代码:
import random
import asyncio
async def func(i):
print(f"异步任务func{i}任务执行了")
t = random.randint(1, 10)
await asyncio.sleep(t) # 遇到IO耗时操作,自动化切换到tasks中的其他任务
print(f"异步任务func{i}任务结束了")
return f"func{i}执行结果,耗时:{t}秒" # 此处的返回值,最终在python底层会被分装一个可等待对象
def callback(res):
print(res.result())
async def main():
task_list = []
# 注冊创建10个协程
for i in range(10):
task = asyncio.create_task(func(i))
task.add_done_callback(callback)
task_list.append(task)
await asyncio.wait(task_list)
if __name__ == '__main__':
asyncio.run(main())
高性能的事件循环-uvloop¶
uvloop是一个第三方模块,专门用于替代asyncio内置的事件循环loop的。替代了以后,可以让asyncio得到性能的提高,理论上使用uvloop以后的asyncio比原来没有替代前,提升2倍的执行效率,性能可以追上go的协程性能。
安装
uvloop主要是底层替换了asyncio的loop,但是在其他的功能的代码使用上还是沿用了asyncio的操作,所以除了事件循环引用的这一句以外,原来的代码怎么编写,以后也是怎么编写。
注意:uvloop不能在windows系统下使用,原因是因为uvloop的实现是基于IO多路复用技术里面的epoll模型。
import random
import asyncio
import uvloop
asyncio.set_event_loop_policy(uvloop.EventLoopPolicy())
async def func():
print(f"异步任务func任务执行了")
await asyncio.sleep(3) # 遇到IO耗时操作,自动化切换到tasks中的其他任务
print(f"异步任务func任务结束了")
return f"func执行结果" # 此处的返回值,最终在python底层会被分装一个可等待对象
if __name__ == '__main__':
ret = asyncio.run(func())
print(ret)
# 实际上,可以这么理解,uvloop就是一个猴子补丁,把asyncio里面的loop进行了替代重写。
# loop原来提供的所有操作,uvloop也有。
我们后面学习到的django里面的uvicorn异步web服务器底层使用的uvloop事件循环。
Future对象¶
可等待对象¶
可等待对象(awaitable),就是能在await表达式中使用的对象,可以是coroutine 或是具有__await__()方法的对象。
可等待对象的__await__方法的返回值必须是一个迭代器对象。
import asyncio
class B(object):
"""迭代器"""
def __iter__(self):
return self
def __next__(self):
raise StopIteration('end')
class A(object):
"""可等待对象的类"""
def __await__(self):
return B() # B()就是一个迭代器
async def main():
s = await A() # 可等待对象
print(s)
if __name__ == '__main__':
task = main()
loop = asyncio.run(task)
认识Future对象¶
我们在前面的学习中了解到,await后面跟着可等待对象(awaitable object),那么在之前的asyncio模块使用时,我们通过create_task创建协程对象,并且使用await 后面跟着协程对象就可以获取到返回结果了,那么之前所操作的协程对象是谁呢?通过打印可以看到是Task对象。
代码:
import asyncio
async def func():
print("func任务执行了!")
await asyncio.sleep(2)
print("func任务结束了!")
return 'func的执行结果'
async def main():
task = asyncio.create_task(func())
ret1 = await task
print(f"ret1={ret1}")
if __name__ == '__main__':
asyncio.run(main())
而在前面学习过程中可以知道,asyncio.createtask方法的底层源码实际上就是获取事件循环的引用对象loop,并执行loop.createtask方法来创建一个task对象,所以asyncio.create_task方法在本质上是将coroutine协程对象封装成task对象,并将协程立即加入事件循环,同时追踪与记录协程的状态(也可以叫做记录现场)。而如果我们不使用await关键字,来接收结果的话,则可以通过task方法提供的result方法来获取结果(我们前面在学习获取任务返回结果时演示的python3.7之前的写法中有展示)。
import asyncio
import inspect # 一个类反射模块,用于判断类型等等
from asyncio.futures import Future
from asyncio.tasks import Task
async def func():
print("func任务执行了!")
await asyncio.sleep(2)
print("func任务结束了!")
return 'func的执行结果'
if __name__ == '__main__':
loop = asyncio.get_event_loop()
task = loop.create_task(func())
loop.run_until_complete(task)
ret = task.result() # 此处获取结果,因此await task 的作用就是等价于这句话,只是await使用过程,语法要求必须把await写在协程函数中
print(f"函数的返回结果:{ret}")
# print(inspect.iscoroutine(func())) # True func()的返回值是一个协程对象
print(inspect.isawaitable(task)) # True task是一个可等待对象
print(isinstance(task, Task)) # True 证明了task对象是Task类的实例
print(issubclass(Task, Future)) # True 证明了Task类是Future的子类
print(isinstance(task, Future)) # True
那么,如果我们点击result查看源码的话,可以发现,实际上result方法根本不是Task类提供的,而是一个叫Future类提供的,那么这个Future类是什么呢?ok,实际上我们编写异步协程中所有的方法的结果处理操作,实际上都是基于Future对象提供的操作来完成的。Future是一个相对更偏向底层的可等待对象(awaitable object),它提供了异步编程中的最终结果的处理操作,所以我们一般把Future也叫异步回调结果对象,虽然平时使用的是Task对象,但对于结果的处理本质是基于Future对象来实现的,Task是Futrue的子类。
创建Future对象¶
代码:
import asyncio
async def main():
# 获取当前正在运行的事件循环引用对象
loop = asyncio.get_running_loop()
# # 创建一个任务(Future对象),这个任务什么都不干。
fut = loop.create_future()
# 等待任务最终结果(Future对象),没有结果则会一直等下去。
await fut # 这里可以看到Future对象可以直接被await所使用
if __name__ == '__main__':
asyncio.run(main())
Future对象的工作流程¶
代码:
import asyncio
async def func(fut):
print("func1任务执行了!")
await asyncio.sleep(2)
print("func1任务结束了!")
fut.set_result("func1执行结果")
# return "func1执行结果" # 在task对象的内部,使用Future.set_result进行了结果的设置
# 没有返回值了!!!
async def main():
# 获取当前事件循环
loop = asyncio.get_running_loop()
# 创建一个任务(Future对象),没绑定任何行为,则这个任务永远不知道什么时候结束。
fut = loop.create_future()
# 创建一个任务(Task对象),绑定了func协程任务函数,函数内部在2s之后通过fut.set_result设置返回值。
# 即手动设置future任务的最终结果,那么fut就可以结束了。
await loop.create_task(func(fut))
# 等待 Future对象获取 最终结果,否则一直等下去
data = await fut
print(f"{data=}")
if __name__ == '__main__':
asyncio.run(main())
Future对象本身与协程任务函数之间不进行绑定,所以想要让事件循环获取Future的结果,则需要手动设置。而Task对象继承了Future对象,其实就对Future对象进行扩展,他可以实现在对应绑定的函数执行完成之后,自动执行set_result,从而实现自动结束,自动返回结果给await Future对象语句。
注意:支持 await xxx语法的xxx对象都是可等待对象,所以协程对象、Task对象、Future对象都是可等待对象。
而除了上面2种方式可以创建Future对象以外,在asyncio模块中的事件循环对象还提供了runinexecutor把本身不支持异步的对象转换成Future异步对象,所以基于这个方法,我们可以实现把同步任务转异步任务的效果。
同步代码异步化¶
在项目以协程式的异步编程开发时,如果要使用一个第三方模块,那么这个模块必须要实现异步才能与协程进行交替执行,否则要么报错,要么就阻塞执行,所以,为了提高程序的性能,就需要把不支持协程式异步编程的第三方模块转换成异步。
import asyncio
import os.path
# requests默认是不支持协程异步的,是一个同步网络请求模块
import requests
async def get_img(i, url):
# 发送网络请求,下载图片
print(f"开始下载{i+1}:", url)
# 同步代码,发起网络请求
# response = requests.get(url)
# 同步转异步,让程序遇到网络下载图片的IO请求,自动化切换到其他任务
loop = asyncio.get_running_loop()
# run_in_executor(None, 同步阻塞函数或方法名, 函数的参数1,,函数的参数2,函数的参数3....)
response = await loop.run_in_executor(None, requests.get, url)
print(f'第{i+1}张图片下载完成')
# 图片保存到本地文件
filename = os.path.basename(url)
with open(f"images/{filename}", mode='wb') as f:
f.write(response.content)
if __name__ == '__main__':
url_list = [
'https://pic.netbian.com/uploads/allimg/220512/011323-16522892039531.jpg',
'https://pic.netbian.com/uploads/allimg/210831/102129-163037648996ad.jpg',
'https://pic.netbian.com/uploads/allimg/210827/235918-1630079958cd73.jpg'
]
tasks = [get_img(i, url) for i, url in enumerate(url_list)]
loop = asyncio.get_event_loop()
loop.run_until_complete(asyncio.wait(tasks))
代码调整:
import asyncio
import os.path
# requests默认是不支持协程异步的,是一个同步网络请求模块
import requests
async def get_img(i, url):
# 发送网络请求,下载图片
print(f"开始下载{i+1}:", url)
# 同步代码,发起网络请求
# response = requests.get(url)
# 同步转异步,让程序遇到网络下载图片的IO请求,自动化切换到其他任务
loop = asyncio.get_running_loop()
# run_in_executor(None, 同步阻塞函数或方法名, 函数的参数1,,函数的参数2,函数的参数3....)
response = await loop.run_in_executor(None, requests.get, url)
await loop.run_in_executor(None, save_image, url, response)
print(f'第{i+1}张图片下载完成')
def save_image(url, response):
# 图片保存到本地文件
filename = os.path.basename(url)
with open(f"images/{filename}", mode='wb') as f:
f.write(response.content)
if __name__ == '__main__':
url_list = [
'https://pic.netbian.com/uploads/allimg/220512/011323-16522892039531.jpg',
'https://pic.netbian.com/uploads/allimg/210831/102129-163037648996ad.jpg',
'https://pic.netbian.com/uploads/allimg/210827/235918-1630079958cd73.jpg'
]
tasks = [get_img(i, url) for i, url in enumerate(url_list)]
loop = asyncio.get_event_loop()
loop.run_until_complete(asyncio.wait(tasks))
同步转异步的原理¶
基于线程池或进程池,把同步函数放到池的一个线程/进程中异步执行,以达到和协程异步协调运行的效果。
import time
import asyncio
from asyncio.futures import Future as Future1
from concurrent.futures import ProcessPoolExecutor, ThreadPoolExecutor
from concurrent.futures import Future as Future2
def func1():
print("func1任务执行了!")
time.sleep(2)
print("func1任务结束了!")
return "func1执行结果"
def func2():
print("func2任务执行了!")
time.sleep(2)
print("func2任务结束了!")
return "func2执行结果"
async def main():
loop = asyncio.get_running_loop()
"""
loop.run_in_executor的第1个参数实际上是池(Pool),如果传递的参数值是None,则默认创建线程池,然后把func1放到线程池中异步执行
也就是说loop.run_in_executor的内部底层代码的执行流程:
第1步:内部会先调用ThreadPoolExecutor的submit方法去线程池中申请一个线程去执行func1函数,并返回一个concurrent.futures.Future对象
第2步:调用asyncio.wrap_future将concurrent.futures.Future对象包装为asyncio.Future对象。
因为concurrent.futures.Future对象没有实现__await__方法,所以不支持await语法,所以需要包装为 asycio.Future对象 才能使用。
"""
# fut1 = loop.run_in_executor(None, func1)
# fut2 = loop.run_in_executor(None, func2)
# print(type(fut1) is Future1) # True
# print(type(fut1) is Future2) # False
#
# result1 = await fut1
# result2 = await fut2
#
# print(f"{result1=}")
# print(f"{result2=}")
# 2. 把同步函数放到线程池中,申请一个线程异步执行函数
with ThreadPoolExecutor() as pool: # 创建一个线程池
fut = loop.run_in_executor(pool, func1) # 把func1放到线程池申请一个线程异步执行,并把结果包装成asyncio的Future对象
print(type(fut))
result = await fut
print(f"线程:{result=}")
# 3. 把同步函数放到进程池中,申请一个进程异步执行函数
with ProcessPoolExecutor() as pool:
fut = loop.run_in_executor(pool, func1)
print(fut)
result = await fut
print(f"进程:{result=}")
if __name__ == '__main__':
asyncio.run(main())
异步可迭代对象¶
异步可迭代对象(asynchronous iterable)就是可在async for语句中被使用的对象。必须通过 __aiter__() 方法返回一个异步可迭代器(asynchronous iterator)。默认的可迭代对象是无法被使用在async for语句中的,原因是默认的可迭代对象并没有实现__aiter__方法。
代码:
import asyncio
import random
import time
class Time(object):
""" 异步迭代器 """
def __aiter__(self):
return self
async def __anext__(self):
val = await asyncio.sleep(random.random(), time.time())
if not val:
raise StopAsyncIteration
return val
# list本身只是一个可迭代对象的类
# 基于list创建了子类List,只实现了__aiter__方法,所以List类创建出来的对象就是一个异步可迭代对象。
class List(list):
"""异步可迭代对象"""
def __aiter__(self): # __aiter__方法的返回值必须是一个异步迭代器
return Time()
async def main():
# 循环异步可迭代对象,可以使用async for进行遍历,则遍历过程中,执行的是 __aiter__方法,__aiter__方法的返回值必须是异步迭代器
# 注意:如果把异步可迭代对象,使用for进行遍历,则遍历过程中,执行的是__iter__方法,__iter__方法的返回值必须是迭代器
async for item in List([1, 2, 3, 3]):
print(item)
if __name__ == '__main__':
asyncio.run(main())
异步迭代器¶
异步迭代器(asynchronous iterator),实现了__aiter__() 和 __anext__() 方法的异步可迭代对象。__anext__ 必须返回一个可等待对象(awaitable)。同理,默认的迭代器也是无法被使用在async for语句中的。
async for会处理异步迭代器的__anext__()方法所返回的可等待对象,直到其引发 StopAsyncIteration 异常。
代码:
import asyncio
import random
import time
class Time(object):
""" 异步迭代器 """
def __aiter__(self):
return self
async def __anext__(self):
val = await asyncio.sleep(1, time.time())
if not val:
raise StopAsyncIteration
return val
async def main():
# 同步的迭代器与异步迭代器在提取数据的时候,都是基于同步获取结果的。
async for item in Time():
print(item)
if __name__ == '__main__':
asyncio.run(main())
异步上下文管理器¶
只要对象定义了 __aenter__() 和 __aexit__() 方法就是一个异步上下文管理器对象, 可以 async with 语句中的环境进行上下文控制。
代码:
import socket
import asyncio
class Sniffer(object):
"""网络嗅探器"""
def __init__(self, url, port, timeout=3):
self.url = url
self.port = port
self.timeout = timeout
self.socket = socket.socket()
self.socket.settimeout(timeout)
async def connect(self):
"""嗅探连接远程服务器,查看指定端口是否开启了"""
loop = asyncio.get_running_loop()
try:
await loop.run_in_executor(None, self.socket.connect, (self.url, self.port))
return True # 表示当前端口是开放的
except:
return False # 表示当前端口是没有开放
async def __aenter__(self):
print(f"开始连接端口:{self.port}")
self.result = await self.connect()
return self.result
async def __aexit__(self, exc_type, exc, tb):
"""异步关闭远程socket连接"""
if self.socket:
self.socket.close()
print(f"结束连接端口:{self.port}")
async def main():
async with Sniffer("192.168.233.129", 22) as f:
print(f)
if __name__ == '__main__':
asyncio.run(main())
异步http网络模块-aiohttp¶
自从python出了asyncio以后,python的异步编程就不再局限于进程和线程以及之前采用各种方式途径实现的协程。python开发中基于asyncio发展出了非常多适用于实现异步编程的各种模块。
对于我们前面使用的requests这个http网络请求模块,实际上在异步编程里面,因为requests的网络请求会被线程识别阻塞,所以针对异步编程下,就有开发者开发了异步编程里面的异步网络请求模块,其中比较常用的有httpx与aiohttp,httpx的性能比requests快,但是aiohttp要慢,因此在异步编程中,我们经常使用的是aiohttp。
aiohttp基于requests模块的异步实现,但是比requests要功能更多,因此aiohttp的部分功能使用时与requests的使用非常类似的,但是aiohttp必须配合asyncio模块来进行使用。aiohttp不仅可以发送网络请求,还可以实现异步http web服务器。
代码:
import asyncio
import aiohttp
"""针对Event loop is closed报错的解决方案有3种方案"""
# 1. linux或mac X OS系统下 改成uvloop
# import uvloop
# asyncio.set_event_loop_policy(uvloop.EventLoopPolicy())
# 2. windows系统
asyncio.set_event_loop_policy(asyncio.WindowsSelectorEventLoopPolicy())
async def func():
async with aiohttp.ClientSession() as session:
async with session.get("https://pic.netbian.com/uploads/allimg/220512/011323-16522892039531.jpg") as response:
with open("1.png", "wb") as f:
f.write(await response.read())
if __name__ == '__main__':
asyncio.run(func())
# 3. 不要使用run方法,改成python3.7以前的写法
# loop = asyncio.get_event_loop()
# loop.run_until_complete(func())